LDef and bytecodes
LDef, short for Language Definition format, is a standard I have been formulating for a couple of years. I have taken my experience with writing various compilers and parsers, and also my experience of writing RTL’s and combined it all into a standard.
 LDef is a way for anyone to create their own programming language. Just like popular libraries and packages deals with the low-level stuff, like Gr32 which is an excellent graphics library — LDef deals with the hard stuff and leaves you with the pleasant job of defining what the language should look like.
LDef is a way for anyone to create their own programming language. Just like popular libraries and packages deals with the low-level stuff, like Gr32 which is an excellent graphics library — LDef deals with the hard stuff and leaves you with the pleasant job of defining what the language should look like.
The idea is to make a language construction kit if you like, where the underlying engine is flexible enough to express the languages we know and love today – and also powerful enough to express new ideas. For example: let’s say you want to create an awesome new game system (just as an example, it applies to any system that can be automated). You have the means and skill to create the actual engine – but how are you going to market it? You will be up against monoliths like Unity and simple “click and play” engines like ClickTeam Fusion, Game Maker and the likes.
Well, the only way to make good games is hard work. There is no two ways about it. You can fake your way only so far – so at the end of the day you want to give your users something solid.
In our example of publishing a game-engine, I think that you would stand a much better chance of attracting users if you hooked that engine up to a language. A language that is easy to use, easy to learn and with commands that are both specific and non-specific to your engine.
There are some flavours of Basic that has produced knock-out games for decades, like BlitzBasic. That language alone has produced hundreds of titles for both PC, XBox and even Nintendo. So it’s insanely fast and not a pushover.
And here is the cool part about LDEF: namely that it makes it easy for you to design your own languages. You can use one of the pre-defined languages, like object pascal or visual basic if that is what you like – but ultimately the fun begins when you start to experiment with new ideas and language features. And it’s fun when you get to that point, because all the nitty gritty is handled. You get to focus on the superficial stuff like syntax and high level functions. So you can shave off quite a bit of development time and make coding fun again!
The paradox of faster bytecodes
Bytecodes used to be to slow for anything substantial. On 16-bit machines bytecodes were used in maybe one language (that I know of) and that was the ‘E’ compiler. The E language was maybe 30 years ahead of its time and is probably the only language I can think of that fits cloud programming like hand in glove. But it was also an excellent system automation language (scripting) and really turned some heads back in the late 80s and early 90s. REXX was only recently added to OS X, some 28 years after the Amiga line of computers introduced it to the general public.

Bytecode dump of a program compiled with the node.js version of the compiler
In modern times bytecodes have resurfaced through Java and the .NET framework which for some reason caused a stir in the whole development community. I honestly never bought into the hype, but I am old enough to remember the whole story – so I’m probably not the Microsoft demographic anyways. Java hyped their virtual machine opcodes to the point of exhaustion. People really are stupid. Man did they do a number on CEO’s and heads of R&D around the world.
Anyways, end of the story was that Intel and AMD went with it and did some optimizations that could help bytecodes run faster. The stack was optimized with Java, because let’s face it – it is the proverbial assault on the hardware. And the cache was expanded on command from the emper.. eh, Microsoft. Also (if I remember correctly) the “jump to pointer” and various branch instructions were made to execute faster. I remember reading about this in Dr. Dobbs Journal and Microsoft Developer Magazine; granted it was a few years ago. What was interesting is the symbiotic relationship that exists between Intel and Microsoft, I really didn’t know just how closely knit these guys were.
Either way, bytecodes in 2017 is capable of a lot more than they ever were on 16-bit and early 32-bit systems. A cpu like Intel i5 or i7 will chew through bytecodes like a warm knife on butter. It depends on how you orchestrate the opcodes and how much work you delegate to the various instructions.
Modeled instructions
Bytecodes are cool but they have to be modeled right, or its all going to end up as a bloated, slow and limited system. You don’t want to be to low-level, otherwise what is the point of bytecodes? Bytecodes should be a part of a bigger picture, one that could some day be modeled using FPGA’s for instance.
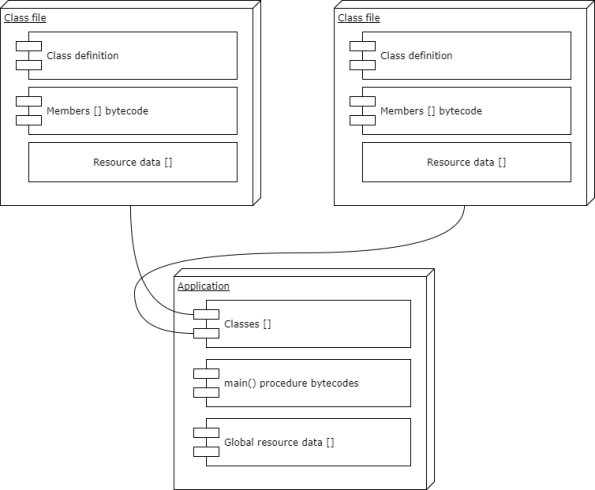
The LDef format is very flexible. Each instruction is ultimately a single 32-bit longword (4 bytes) where each byte holds key information about the command, what data is forward in the cache and how it should be read.
The byte organization is:
- 0 – Actual opcode
- 1 – Instruction layout
Depending on the instruction layout, the next two bytes can hold different values. The instruction layout is a simple value that defines how the data for the instruction is passed.
- Constant to register
- Variable to register
- Register to register
- Register to variable
- Register to stack
- Stack to register
- Variable to variable
- Constant to variable
- Stack to variable
- Program counter (PC) to register
- Register to Program counter
- ED (exception data) to register
- Register to exception-data
As you can probably work out from the information here, this list hints to some archetectual features. Variables are first class citizens in LDef, they are allocated, managed and released using instructions. Constants can be either automatically handled and references by id (a resource chunk is linked to the class binary) or “in place” and compiled directly into the assembly as part of the instruction. For example
load R[0], "this is a test"
This line of code will take the constant “this is a test” and move it into register #0. You can choose to have the text-data stored as a proper resource which is appended to the compiled bytecode (all classes and modules have a resource chunk) or just compile “as is” and have the data read directly. The first option is faster and something you can adjust with compiler optimization options. The second option is easier to work with when you debug since you can see the data directly as a part of the debug memory dump.
And last but not least there are registers. 32 of them in number (so for the low-level coders out there you should have few limitations with regards to register mapping). All operations (like divide, multiply etc) operate on registers only. So to multiply two variables they first have to be moved into registers and the multiplication is executed there – then you can move the result to a variable afterwards.

LDef assembly code. Simple but extremely effective
The reason registers is used in my runtime system – is because you will not be able to model a FPGA with high-level concepts like “variables” should someone every try to implement this as hardware. Things like registers however is very easy to model and how actual processors work. You move things from memory into a cpu register, perform an action, and then move the result back into memory.
This is where Java made a terrible mistake. They move all data onto the stack and then call the operation. This simplifies execution of instructions since there is never any registers to keep track of, but it just murders stack-space and renders Java useless on mobile devices. The reason Google threw out classical Java (e.g Java as bytecodes) is due to this fact (and more). After the first android devices came out they quickly switched to a native compiler – because Java was too slow, to power-hungry and required too much memory (especially stack space) to function properly. Battery life was close to useless and the only way to save Java was to go native. Which is laughable because the entire point of Java was mobility, “compile once run everywhere” — yeah well, that didn’t turn out to well did it 😀
Dot net improved on this by adding a “load resource” type instruction, where each method will load in the constant data by number – and they are loaded into pre-defined slots (the variables you have used naturally). Then you can execute operations in typical “A + B to C” style (actually all of that is omitted since the compiler already knows both A, B and C). This is much more stack friendly and places performance penalty on the common language runtime (CLR).
Sadly Microsoft’s platform, like everything Microsoft does, requires a pretty large infrastructure. It’s not simple, elegant and fast – it’s more monolithic, massive and resource hungry. You don’t see .net being the first thing ported to a new platform. You typically see GCC followed by Freepascal.
LDef takes the bytecode architecture one step further. On assembly level you reference data using identifiers just like .net, and each instruction is naturally executed by the runtime-engine – but data handling is kept within the virtual realm. You are expected to use the registers as temporary holding slots for your information. And no operations are ever done directly on a variable.
The benefit of this is:
- Better payload balancing
- Easier to JIT since the architecture is closer to real assembly
- Retains important aspects of how real hardware works (with FPGA in mind)
So there are good reasons for the standard, all of them very good.
C like intermediate language
With assembler so clearly defined you would expect assembly to be the way you work. In essence that what you do, but since OOP is built into the system and there are structures you are expected to populate — structures that would be tedious to do in raw unbridled assembler, I have opted for a C++ inspired intermediate language.

The LDEF assembler kitchen sink
You would half expect me to implement pascal, but truth be told pascal parsing is more complex than C parsing, and C allows you to recycle parsers more easily, so dealing with sub structures and nested regions is less maintainance and easier to write code for.
So there is no spesific reason why I picked C++ as a intermediate language. I would prefer pascal but I also think it would cause a lot of confusion since object pascal will be the prime citizen of LDef languages. My other language, N++ also used curley brackets so I’m honestly not strict about what syntax people prefer.
Intermediate language features supported are:
- Class declarations
- Struct declarations
- Parameter to register mapping
- Before mehod code (enter)
- After method code (leave)
- Alloc section for class fields
- Alloc section for method variables
The before and after code for methods is very handy. They allow you to define code that should execute before the actual procedure. On a higher level when designing a new language, this is where you would implement custom allocation, parameter testing etc.
So if you call this method:
function testcode() {
enter {
writeln("this is called before the method entry");
}
leave {
writeln("this is called after the method exits");
}
writeln("this is the method body");
}
Results in the following output:
this is called before the method entry this is the method body this is called after the method exits
When you work with designing your language, you eventually.
Truly portable
Now I have no aspirations in going into competition with neither Oracle, Microsoft or anyone in between. Like most geeks I do things I find interesting and enjoy working within a field of computing that is stimulating and personally rewarding.
Programming languages is an area where things havent really changed that much since the golden 80s. Sure we have gotten a ton of fancy new software, and the way people use languages has changed – but at the end of the day the languages we use havent really changed that much.
JavaScript is probably the only language that came out of the blue and took the world by storm, but that is due to the central role the browser holds for the internet. I sincerely doubt JavaScript would even have made a dent in the market otherwise.
LDef is the type of toolkit that can change all this. It’s not just another language, and it’s not just another bytecode engine. A lot of thought has gone into its architecture, not just notions of “how can we do this or that”, but big ideas about the future of computing and how IOT will sculpt the market within 5-8 years. And the changes will be permanent and irrevocable.
Being able to define new languages will be utmost important in the decade ahead. We don’t even know the landscape yet but we can extrapolate some ideas based on where technology is going. All of it in broad strokes of course, but still – there are some fundamental facts about computers that the timeless and havent aged a day. It’s like mathematics, the Pythagorean theorem may be 2500 years old but it’s just as valid today as it was back then. Principles never die.
I took the example of a game engine at the start of this article. That might have been a poor choice for some, but hopefully the general reader got the message: the nature of control requires articulation. Regardless if you are coding an invoice system or a game engine, factors like time, portability and ease of use will be just as valid.
There is also automation to keep your eye on. While most of it is just media hype at this point, there will be some form of AI automation. The media always exaggerates things, so I think we can safely disregard a walking, self-aware Terminator type robot replacing you at work. In my view you can disregard as much as 80% of what the media talks about (regardless of topic). But some industries will see wast improvement from automation. The oil and gas sector are the most obvious. A the moment security is as good as humans can make them – which means it is flawed and something goes wrong every day around the globe. But smart pumping stations and clever pressure measurements and handling will make a huge difference for the people who work with oil. And safer oil pipelines means lives saved and better environmental control.
The question is, how do we describe programs 20 years from now? Is our current tools up for the reality of IOT and billions of connected devices? Do we even have a language that runs equally well as a 1000 instance server-cluster as it would as a stand alone program on your desktop? When you start to look into parallel computing and multi-cluster data processing farms – languages like C# and C++ makes little sense. Node.js is close, very close, but dealing with all the callbacks and odd limitations of JavaScript is tedious (which is why we created Smart Pascal to begin with).
The future needs new things. And for that to happen we first need tools to create them. Which is where my passion is.
Node, native and beyond
When people create compilers and programming languages they often do so for a reason. It could be that their own tools are lacking (which was my initial motivation), or that they have thought of a better way to achieve something; the reasons can be many. In Microsofts case it was revenge and spite, since they were unsuccessful in stealing Java away from Sun Microsystems (Oracle now owns Java).
LDef binaries are fairly straight forward. The less fluff the better
Point is, you implement your idea using the language you know – on the platform you normally use. So for me that is object pascal on windows. I’m writing object pascal because while the native compiler and runtime is written in Delphi – it is made to compile under Freepascal for Linux and OS X.
But the primary work is done in Smart Pascal and compiled to JavaScript for node.js. So the native part is actually a back-port from Smart. And there is a good reason I’m doing it this way.
First of all I wanted a runtime and compiler system that would require very little to run. Node.js has grown fat in features over the past couple of years – but out of the box node.js is fast, portable and available almost anywhere these days. You can write some damn fast and scalable cloud servers with node (and with fast i mean FAST, as in handling thousands of online gamers all playing complex first person worlds) and you can also write some stable and rock solid system services.
Node is turning into a jack of all trades, capable of scaling and clustering way beyond what native software can do. Netflix actually re-wrote their entire service stack using node back in 2014. The old C++ and ASP approach was not able to handle the payload. And every time they did a small change it took 45 minutes to compile and get a binary to test. So yeah, node.js makes so much more sense when you start looking a big-data!
So I wanted to write LDef in a way that made it portable and easy to implement. Regardless of platform, language and features. Out of the box JavaScript is pretty naked stuff and the most advanced high-level feature LDef uses is buffers to deal with memory. everything else is forced to be simple and straight forward. No huge architecture or global system services, just a small and fast runtime and your binaries. And that’s all you need to run your compiled applications.
Ultimately, LDef will be written in LDef itself and compile itself. Needing only a small executable stub to be ported to a new platform. Most of mono C# for Linux is written in C# itself – again making it super easy to move mono between distros and operating systems. You can’t do that with the Visual Studio, at least not until Microsoft wants you to. Neither would you expect that from Apple XCode. Just saying.
The only way to achieve the same portability that mono, freepascal and C/C++ has to offer, is naturally to design the system as such from the beginning. Keep it simple, avoid (operatingsystem) globalization at all cost, and never-ever use platform bound APIs except in the runtime. Be Posix but for everything!
Current state of standard and licensing
The standard is currently being documented and a lot of work has been done in this department already. But it’s a huge project to document since it covers not only LDEF as a high-level toolkit, but stretches from the compiler to the source-code it is designed to compile to the very binary output. The standard documentation is close to a book at this stage, but that’s the way it has to be to ensure every part is understood correctly.
But the question most people have is often “how are you licensing this?”.
Well, I really want LDEF to be a free standard. However, to protect it against hijacking and abuse – a license must be obtained for financial entities (as in companies) using the LDEF toolkit and standard in commercial products.
I think the way Unreal software handles their open-source business is a great example of how things should be done. They never charge the little guy or the Indie developer – until they are successful enough to afford it. So once sales hits a defined sum, you are expected to pay a small percentage in royalties. Which is only fair since Unreal engine is central to the software to begin with.
So LDef is open source, free to use for all types of projects (with an obligation to pay a 3% royalty for commercial products that exceeds $4999 in revenue). Emphasis is on open source development. As long as the financial obligations by companies and developers using LDEF to create successful products is respected, only creativity sets the limit.
If you use LDEF to create a successful product where you make 50.000 NKR (roughly USD 5000) you are legally bound to pay 3% of your product revenue monthly for the duration of the product. Which is extremely little (3% of $5000 is $150 which is a lot less than you would pay for a Delphi license, the latter costing between upwards of USD 3000).


You must be logged in to post a comment.