Archive
Drag and drop with smart pascal
Drag and drop under HTML5 is incredibly simple; even more simple than Delphi’s mechanisms. Having said that it can be a PITA to work with due to the async nature of the JavaScript API.
This functionality is just begging to be isolated in a non-visual controller (read: component), and it’s on my list of RTL features. But it will have to wait until we have wiped the list clean.

Drag and drop is useful for many web applications
Anyways, people asked me about a simple way to capture a drag & drop event and kidnap the file-data without any type for form tags involved. So here is a very simple ad-hoc example.
The FView variable is a reference to a visible control. In this case the form itself, so that you can drop files anywhere.
FView.handle.ondragover := procedure (event: variant)
begin
// In order to hijack drag & drop, this event must prevent
// the default behavior. So we hotwire it
event.preventDefault();
end;
FView.Handle.ondrop := procedure (event: variant)
begin
event.preventDefault();
var ev := event.dataTransfer;
if (ev) then
begin
if (ev.items) then
begin
for var x:=0 to ev.items.length-1 do
begin
var LItem := ev.items[x];
if (LItem) then
begin
if string(LItem.kind).ToLower() = "file" then
begin
var file := LItem.getAsFile();
var reader: variant;
asm
@reader = new FileReader();
end;
reader.onload := procedure (data: variant)
begin
if reader.readyState = 2 then
begin
writeln("File data ready:");
var binbuffer := reader.result;
var raw: TDefaultBufferType;
asm
@raw = new Uint8Array(@binbuffer);
end;
var Buffer := TBinaryData.Create();
Buffer.AppendBuffer(raw);
writeln(buffer.ToBase64());
end;
end;
reader.readAsArrayBuffer(file);
end;
end;
end;
end;
end;
end;
Object models, a Smart Pascal example
Most information developers work with is hierarchal and organized in a classical parent and child manner. Parent-child relationships is so universal that they are everywhere, from how visual controls are organized to how elements in a document is stored. No matter if it’s a visual treeview in Delphi, an html element in a document or entries in a pdf-file; it’s pretty much all organized in a series of inter-linked, parent-child relationships.
Since parent-child trees is so universal, developers usually end up with a unit that contains a couple of simple base-classes. Typically these classes are used to create a model of things. The tree can contain the actual data itself – or more commonly, it’s used to represent a model that is later processed or realized visually.

Most frameworks are essentially parent-child hierarchies
Here is an example of such a unit. It compiles under Smart Pascal and should work fine for most versions. It has virtually no dependencies.
Populate the data property with whatever data you want to represent, then you can enumerate and work with the model. What you use it for is eventually up to you. I use it a lot when dealing with menus; it makes it easier to define menus and sub-menus and then simply feed the model to a construction routine.
unit DataNodes;
interface
uses
System.Types;
type
// for older SMS versions that lack "system.types", un-remark this:
// TEnumResult = (erContinue = $A0, erBreak = $10);
TCustomDataNode = class;
TCustomDataNodeList = array of TCustomDataNode;
TDataNodeEnumEnterProc = function (const Root: TCustomDataNode): TEnumResult;
TDataNodeEnumExitProc = function (const Root: TCustomDataNode): TEnumResult;
TDataNodeEnumProc = function (const Child: TCustomDataNode): TEnumResult;
TDataNodeCompareProc = function (const Value: variant): boolean;
TCustomDataNode = class
protected
property Parent: TCustomDataNode;
property Caption: string;
public
property Data: variant;
property Children: TCustomDataNodeList;
procedure Clear;
function Search(const Compare: TDataNodeCompareProc): TCustomDataNode;
procedure ForEach(const Before: TDataNodeEnumEnterProc;
const Process: TDataNodeEnumProc;
const After: TDataNodeEnumExitProc); overload;
procedure ForEach(const Process: TDataNodeEnumProc); overload;
function Serialize: string;
class function Parse(const JSonData: string): TCustomDataNode;
constructor Create(const NodeOwner: TCustomDataNode;
NodeText: string; const NodeData: variant); overload;
constructor Create(const NodeOwner: TCustomDataNode;
const NodeData: variant); overload;
end;
TDataNode = class(TCustomDataNode)
public
property Parent;
property Caption;
end;
TDataNodeTree = class(TCustomDataNode)
public
property Caption;
end;
implementation
//#############################################################################
// TCustomDataNode
//#############################################################################
constructor TCustomDataNode.Create(const NodeOwner: TCustomDataNode;
NodeText: string; const NodeData: variant);
begin
Parent := NodeOwner;
Caption := NodeText;
Data := NodeData;
end;
constructor TCustomDataNode.Create(const NodeOwner: TCustomDataNode;
const NodeData: variant);
begin
Parent := NodeOwner;
Data := NodeData;
end;
function TCustomDataNode.Serialize: string;
begin
asm
@result = JSON.stringify(@self);
end;
end;
class function TCustomDataNode.Parse(const JSonData: string): TCustomDataNode;
begin
asm
@result = JSON.parse(@JSONData);
end;
end;
procedure TCustomDataNode.Clear;
begin
try
for var x := 0 to Children.length-1 do
begin
if Children[x] <> nil then
Children[x].free;
end;
finally
Children.Clear();
end;
end;
function TCustomDataNode.Search(const Compare: TDataNodeCompareProc): TCustomDataNode;
var
LResult: TCustomDataNode;
begin
ForEach( function (const Child: TCustomDataNode): TEnumResult
begin
if Compare(Child.Data) then
begin
LResult := Child;
result := TEnumResult.erBreak;
end;
end);
result := LResult;
end;
procedure TCustomDataNode.ForEach(const Before: TDataNodeEnumEnterProc;
const Process: TDataNodeEnumProc;
const After: TDataNodeEnumExitProc);
begin
if assigned(Before) then
Before(self);
try
if assigned(Process) then
begin
for var LChild in Children do
begin
if Process(LChild) = erBreak then
break;
end;
end;
finally
if assigned(After) then
After(self);
end;
end;
procedure TCustomDataNode.ForEach(const Process: TDataNodeEnumProc);
begin
if assigned(Process) then
begin
for var LChild in Children do
begin
if Process(LChild) = erBreak then
break;
end;
end;
end;
end.
LDef parser done
Note: For a quick introduction to LDef click here: Introduction to LDef.
Great news guys! I finally finished the parser and model builder for LDef!
![]() That means we just need to get the assembler ported. This is presently running fine under Smart Pascal (I like to prototype things there since its faster) – and it will be easy to port it over to Delphi and Freepascal after the model has gone through the steps.
That means we just need to get the assembler ported. This is presently running fine under Smart Pascal (I like to prototype things there since its faster) – and it will be easy to port it over to Delphi and Freepascal after the model has gone through the steps.
I’m really excited about this project and while I sadly don’t have much free time – this is a project I truly enjoy working on. Perhaps not as much as Smart Pascal which is my baby, but still; its turning into a fantastic system.
Thoughts on the architecture
One of the things I added support for, and that I have hoped that Embarcadero would add to Delphi for a number of years now, is support for contract coding. This is a huge topic that I’m not jumping into here, but one of the features it requires is support for entry and exit sections. Essentially that you can define code that executes before the method body and directly after it has finished (before the result is returned if it’s a function).
This opens up for some very clever means of preventing errors, or at the very least give the user better information about what went wrong. Automated tests also benefits greatly from this.
For example, a normal object pascal method looks, for example, like this:
procedure TForm1.MySpecialMethod;
begin
writeln("You called my-special-method")
end;
The basis of contract design builds on the classical and expands it as such:
procedure TForm1.MySpecialMethod;
Before()
begin
writeln("Before my-special-method");
end;
After()
begin
writeln("After my-special-method");
end;
begin
writeln("You called my-special-method")
end;
Note: contract design is a huge system and this is just a fragment of the full infrastructure.
What is cool about the before/after snippets, is that they allow you to verify parameters before the body is even executed, and likewise you get to work on the result before the value is returned (if any).
You mights ask, why not just write the tests directly like people do all the time? Well, that is true. But there will also be methods that you have no control over, like a wrapper method that calls a system library for instance. Being able to attach before/after code for externally defined procedures helps take the edge off error testing.
Secondly, if you are writing a remoting framework where variant data and multi-threaded invocation is involved – being able to check things as they are dispatched means catching potential errors faster – leading to better performance.
As always, coding techniques is a source of argument – so im not going into this now. I have added support for it and if people don’t need it then fine, just leave it be.
Under LDef assembly it looks like this:
public void main() {
enter {
}
leave {
}
}
Well I guess that’s all for now. Hopefully my next LDef post will be about the assembler being ready – leaving just the linker. I need to experiment a bit with the codegen and linker before the unit format is complete.
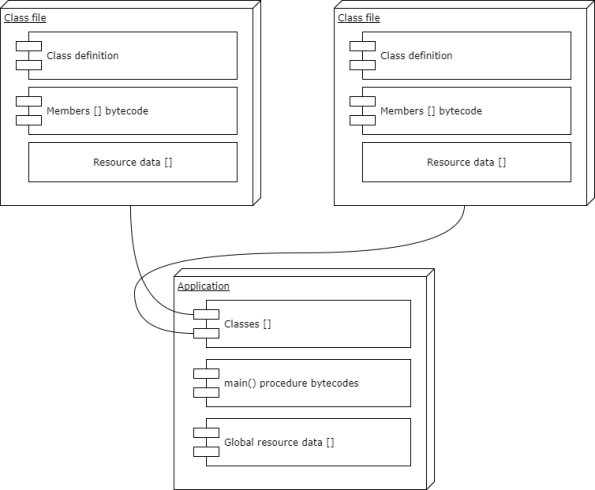
The bytecode-format needs to include enough information so that the linker can glue things together. So every class, member, field etc. must be emitted in a way that is easy and allows the linker to quickly look things up. It also needs to write the actual, resulting method offsets into the bytecode.
Have a happy weekend!
FMX 4 linux gets an update
The Firemonkey framework that allows you to compile for Linux desktop (Linux x86 server is already supported) just got a nice update. Amoung the changes is a nice Radial Gradient pattern – and several bugs squashed.

This is an awesome addition if you already have Delphi XE 10.2 and if writing Ubuntu desktop applications is something you want – then this is the package to get!
Check it out: http://fmxlinux.com/
Smart Pascal: Amibian vs. FriendOS
This is not a new question, and despite my earlier post I still get hammered with these on a weekly basis – so lets dig into this subject and clean it up.
I fully understand that for non-developers suddenly having two Amiga like web desktops can be a bit confusing; especially since they superficially at least do many of the same things. But there is actually a lot of co-incidence surrounding all this, as well as evolution of the general topic. People who work with a topic will naturally come up with the same ideas from time to time.
But ok, lets dig into this and clear away any confusion
You know about FriendOS right? It looks a lot like Amibian

Custom native web servers has been a part of Delphi for ages, so it’s not that exciting for us
“A lot” is probably stretching it. But ok: FriendOS is a custom server system with a sexy desktop front-end written in HTML5. So you have a server that is custom written to interact with the browser in a special way. This might sound like a revolution to non-developers but it’s actually an established technology; its been a part of Delphi and C++ builder for at least 12 years now (Intraweb being the best example, Raudus another). So if you are wondering why im not dazzled, it’s because this has been there for a while.
The whole point of Amibian.js is to demonstrate a different path; to get away from the native back-end and to make the whole system portable and platform independent. So in that regard the systems are diametrically different.

Custom web servers that talk to your web-app is old news. Delphi developers have done this for a decade at least and it’s not really interesting at this point. Node.js holds much greater promise.
What FriendOS has done that is unique, and that I think is super cool – is to couple their server with RDP (remote desktop protocol) and some nice video streaming for smooth video chat. Again these are off the shelves parts that anyone can add once you have a native back-end, it’s not really hard to code but time-consuming; especially when you are potentially dealing with large number of users spawning threads all over the place. I think Friend-Labs have done an exceptional good job here.
When you combine these features it creates the impression of an operating system like environment. And this is perfectly fine for ordinary users. It all depends on your needs and what exactly you use the computer for.
And just to set the war-mongers straight: FriendOS is not going up against Amibian. it’s going up against ChromeOS, Nayu and and a ton of similar systems; all of them with deep pockets and an established software portfolio. We focus on software development. Not even in the same ballpark.
To be perfectly frank: I see no real purpose for a web desktop except when connected to a context. There has to be an advantage beyond isolating web functions in one place. You need something special that your system does better than others, or different than others. Amibian has been about UAE.js and to run retro games in a familiar environment. And thus create a base that Amiga lovers can build on and play with. Again based on our prefab for customers that make embedded systems and use our compiler and RTL for that.
If you have a hardware product like a NAS, a ticket system or a retro-game machine and want to have a nice web front-end for it: then it makes sense. But there is absolutely nothing in both our systems that you can’t whip-up using Intraweb or Raudus in a few weeks. If you have the luxury of a native back-end, then adding Active Directory support is a matter of dropping a component. You can even share printers and USB devices over the wire if you like, this has been available to Delphi and c++ developers for ages. The “new” factor here, which FriendOS does very well i might add, is connectivity.
This might sound like criticism but it’s really not. It’s honesty and facts. They are going to need some serious cash to take on Google, Samsung, LG and various other players that have been doing similar things for a long time (or about to jump on the same concepts) — Amibian.js is for Amiga fans and people who use Smart Pascal to write embedded applications. We don’t see anything to compete with because Amibian is a prefab connected to a programming language. FriendOS is a unification system.
A programming language doesnt have the aspirations of a communication company. So the whole “oh who is best” or “are you the same” is just wrong.
Ok you say it’s not competing, but why not?
To understand Amibian.js you first need to understand Smart Pascal (see Wikipedia article on Smart Pascal). Smart Pascal (smartmobilestudio.com) is a software development studio for writing software using web technology rather than native machine-code. It allows you to create whatever you like, from games to servers, or kiosk software to the next Facebook clone.
Our focus is on enabling our customers to quickly program robust mobile applications, servers, kiosk software, games or large JavaScript projects; products that would otherwise be hard to manage if all you have is vanilla JavaScript. I mean why spend 2 years coding something when you can do it in 2 months using Smart? So a web desktop is just ridicules when you understand how large our codebase is and the scope of the product.

Under Smart Pascal what people know as Amibian.js is just a project type. There is no competition between FriendOS and Amibian because a web desktop represents a ridicules small piece of our examples; it’s literally mistaking the car for the factory. Amibian is not our product, it is a small demo and prefab (pre fabricated system that others can download and build on) project that people use to save time. So under Smart, creating your own web desktop is a piece of cake, it’s a click, and then you can brand it, expand it and do whatever you like with it. Just like you would any project you create in Visual Studio, Delphi or C++ builder.
So we are not in competition with FriendOS because we create and deliver development tools. Our customers use Smart Pascal to create web environments both large and small, and naturally we deliver what they need. You could easily create a FriendOS clone in Smart if you got the skill, but again – that is but a tiny particle in our codebase.
Really? Amibian.js is just a project under Smart Pascal?
Indeed. Our product delivers a full object-oriented pascal compiler, debugger and IDE. So you can write classes, use inheritance and enjoy all the perks of a high-level language — and then compile this to JavaScript.
You can target node.js, the browser and about 90+ embedded devices out of the box. The whole point of Smart Pascal is to avoid the PITA that is writing large applications in JavaScript. And we do this by giving you a classical programming language that was made especially for application authoring, and then compile that to JavaScript instead.
Amibian.js is just a tiny, tiny part of what Smart Pascal is all about
This is a massive undertaking that started back in 2009/2010 and involves a high-quality compiler, linker, debugger and code generator; a full IDE with a ton of capabilities and last but not least: a huge run-time library that allows you to work with the DOM (document object model, or HTML) and node.js from the vantage point of a programmer.
Most people approach web development as a designer. They write html and then style them using a stylesheet. They work with colors, aspects and pages. Which means people who traditionally write programs falls between two chairs: first they must learn about html and css, and secondly a language which is ill equipped for large scale applications (imagine writing adobe photoshop in nothing but JS. Sure it’s possible, but wouldnt you rather spend a month coding that than a year? In a language that actually makes sense?).
With Smart you approach web development like you do writing programs. You work with visual controls, change properties, write code in response to events. Even writing your own visual controls that you can re-use and inherit from later is both fun and easy. So rather than ending up with a huge was of spaghetti code, which sadly is the fate of most large-scale JavaScript projects — Smart lets you work like you are used to. In a language better suited for the task.
And yes, I was not kidding when I said this was a huge undertaking. The source code in our codebase is close to 2.5 gigabytes. And keep in mind that this is source-code and libraries. So it’s not something you slap together over the weekend.

The Smart source-code is close to 2.5 gigabytes. It has taken years to complete
But why do Amibian and FriendOS both focus on the Amiga?
That is pure co-incidence. The guys over at Friend Labs started out on the Amiga just like we did. So when I updated our desktop project (previously called Quartex Media Desktop) the Amiga look and feel came natural to me.
 I’m a huge retro-computing fan that loves the Amiga. When I sat down to rewrite our window manager I loved the way Amiga OS 4.x looked, so I decided to implement an UI inspired by that.
I’m a huge retro-computing fan that loves the Amiga. When I sat down to rewrite our window manager I loved the way Amiga OS 4.x looked, so I decided to implement an UI inspired by that.
People have to remember that the Amiga was a huge success in Scandinavia, so finding developers that are in their late 30s or early 40s that didn’t own an Amiga is harder than you think.
So the fact that we all root our ideas back to the Amiga is both co-incidence and a mutual passion for a great platform. One that really should have survived the financial onslaught of fat CEO’s and thir minions in the board.
But Amibian does a lot of what FriendOS does?
Probably. JavaScript is multi-tasking by default so if loading external URL’s into window containers, doing live resize and other things is what you refer to then yes. But that is the nature of web programming. Its like creating a bucket if you want to carry water; it is a natural first step of an evolutionary pattern. It’s not like FriendOS is copying us I would imagine.

For the record Smart started back in 2010 and the media desktop came in with the first hotfix, so its been available years before Friend-Labs even existed. Creating a desktop has not been a huge part of what we do because mobile applications, building a rich and solid run-time-library with hundreds of classes for our customers – and making an IDE that is great to use, that is our primary job.
We didn’t even know FriendOS existed. Let alone that it was a Norwegian product.
But you posted that you worked for FriendOS earlier?
Yes I did, very briefly. I was offered a position and I worked there for a month. It was a chance to work side by side with legends like David John Pleasance, ex head of Commodore for europe; and also my childhood hero Francois Lionet, author of Amos Basic for the Amiga way back in the 80’s and 90s.

We never forget our childhood heroes
Sadly we had our wires crossed. I am an awesome object pascal developer, while the guys at Friend-Labs are awesome C developers. I work primarily on Windows while they work mostly on Linux. So in essence they hired a Delphi developer to work in a language he doesn’t know on a platform he havent used.
They simply took for granted that I worked in C/C++, while I took for granted that they used object pascal. Its an easy mistake to make and its not the first time; and probably not the last.
Needless to say the learning curve would be extremely high for any developer (learning a new operating-system and programming language at the same time as you are supposed to be productive).
When my girlfriend suddenly faced a life threatening illness the situation became worse. It was impossible for me to commute or leave her side for the unforeseeable future; so when you add the six months learning curve to this situation; six months of not being able to contribute on the level I am used to; well I am old enough to know how that ends. So I did what was best for everyone and resigned.
Besides, I am a damn good Delphi developer with standing invitation to many companies; so it made more sense to just take a step backwards. Which was not fun because I really enjoyed the short time I was there. But, it was not meant to be.
And that is basically all there is to it.
Ok. But if Smart is a development tool, will it support Friend-OS ?
This is something that I really want to do. But since The Smart Company is a proper company with stocks, shareholders and investors – it’s not a decision I can take on my own. It is something that must be debated by the board. But personally yeah, I would love that.

As they grow, so does the need for proper development tools
One of the reasons I hope FriendOS succeeds is because it’s a win-win situation. The more they expand the more relevant Smart becomes. Say what you will about JavaScript but writing large and complex applications is not easy by any measure.
So the moment we introduce Smart Pascal for Friend, their users will be able to write large applications rapidly, with better time-to-market and consequent ROI. So it’s a win-win. If they succeed then we get a bigger market; If they don’t we havent lost anything.
This may sound extremely self-serving, but Friend-Labs have had the same chance as everyone else to invest in Smart; our investor plans have been available for quite some time, and we have to do what is best for our company.
But what about Amibian, was it just a short thing?
Not at all. It is put on hold for a few months while we release the next generation RTL. Which is probably the biggest update in the history of Smart Pascal. We have a very clear agenda ahead of us and Amibian.js is (as underlined) a very small part of what we do.
But Amibian is written using our next generation RTL, and without that our customers cant really do much with it. So it’s important to get the RTL out first and then work on the IDE to reflect its many new features. After that – Amibian.js development will continue.
The primary target for Amibian.js is embedded devices and kiosk systems, coupled with full-screen web applications and hardware front-ends (NAS and backup devices being great examples). So the desktop will run on affordable, off the shelves hardware starting at $40 and all the way up to the most powerful and expensive x86 boards on the market. Cheap solutions like Raspberry PI, ODroid XU4 and Tinkerboard will deliver what you today need a dedicated $120 x86 board to achieve.

Our desktop will run on many targets and is platform independent by design
This means that our deskop has a wildly different modus operandi. We will not require a constant connection to a remote server. Amibian will happily boot up on a single device, regardless of processor type.
Had we coded our backend using Delphi or C++ builder (native like FriendOS have done) we would have been finished months ago. And I could have caught up with FriendOS in a couple of months if I wanted to. But that is not in our agenda. We have written our server framework for node.js as we coded the desktop – which means it’s platform and OS agnostic by design. If node.js runs, Amibian will run. It wont care if you are running on a $40 embedded board or the latest Intel i9 cpu.
Last words
I really hope this has helped and that the confusion between Amibian.js and our agenda, versus what Friend-Labs is doing, is now clearer.

From Norway with love
I wish Friend-Labs the very best and hope they are successful in their endeavour. They have worked very hard on the product and deserve that. And while I might come over as arrogant at times, im really not.
Web desktops have been around for a long time now (Asustor is my favorite) through Delphi and C++ builder and that is just facts. But that doesn’t mean you can’t put things together in new and interesting ways! Smart itself was first put together by existing technology. It was said to be impossible by many because JavaScript and object pascal are unthinkable companions. But it turned out to be a perfect match.
As for the future – personally I don’t believe in the web-desktop outside a specific context, something to give it purpose if you like. I believe for instance that Amibian.js will be awesome for Amiga users when its running on a $99 ARM laptop. Where the system boots straight into a full-screen desktop and where UAE.js is fully integrated into the core, making retro-gaming and running old programs close to seamless. That I can believe in.
But it would make no sense running Amibian or FriendOS in a browser on top of a Windows desktop or a full Ubuntu X session. Unless the virtual desktop functions as your corporate window with access to company mail, documents and essentially what every web-based intranet already does. So once again we end up with the fact that this has already been done. And unless you create a unique context for it, it just wont have any appeal. This is also why I havent pursued the same tech Friend-Labs have, because that’s not where the exciting stuff is happening.
But I will happily be proven wrong, because that means an even bigger market for us should we decide to support the platform.
LDef and bytecodes
LDef, short for Language Definition format, is a standard I have been formulating for a couple of years. I have taken my experience with writing various compilers and parsers, and also my experience of writing RTL’s and combined it all into a standard.
 LDef is a way for anyone to create their own programming language. Just like popular libraries and packages deals with the low-level stuff, like Gr32 which is an excellent graphics library — LDef deals with the hard stuff and leaves you with the pleasant job of defining what the language should look like.
LDef is a way for anyone to create their own programming language. Just like popular libraries and packages deals with the low-level stuff, like Gr32 which is an excellent graphics library — LDef deals with the hard stuff and leaves you with the pleasant job of defining what the language should look like.
The idea is to make a language construction kit if you like, where the underlying engine is flexible enough to express the languages we know and love today – and also powerful enough to express new ideas. For example: let’s say you want to create an awesome new game system (just as an example, it applies to any system that can be automated). You have the means and skill to create the actual engine – but how are you going to market it? You will be up against monoliths like Unity and simple “click and play” engines like ClickTeam Fusion, Game Maker and the likes.
Well, the only way to make good games is hard work. There is no two ways about it. You can fake your way only so far – so at the end of the day you want to give your users something solid.
In our example of publishing a game-engine, I think that you would stand a much better chance of attracting users if you hooked that engine up to a language. A language that is easy to use, easy to learn and with commands that are both specific and non-specific to your engine.
There are some flavours of Basic that has produced knock-out games for decades, like BlitzBasic. That language alone has produced hundreds of titles for both PC, XBox and even Nintendo. So it’s insanely fast and not a pushover.
And here is the cool part about LDEF: namely that it makes it easy for you to design your own languages. You can use one of the pre-defined languages, like object pascal or visual basic if that is what you like – but ultimately the fun begins when you start to experiment with new ideas and language features. And it’s fun when you get to that point, because all the nitty gritty is handled. You get to focus on the superficial stuff like syntax and high level functions. So you can shave off quite a bit of development time and make coding fun again!
The paradox of faster bytecodes
Bytecodes used to be to slow for anything substantial. On 16-bit machines bytecodes were used in maybe one language (that I know of) and that was the ‘E’ compiler. The E language was maybe 30 years ahead of its time and is probably the only language I can think of that fits cloud programming like hand in glove. But it was also an excellent system automation language (scripting) and really turned some heads back in the late 80s and early 90s. REXX was only recently added to OS X, some 28 years after the Amiga line of computers introduced it to the general public.

Bytecode dump of a program compiled with the node.js version of the compiler
In modern times bytecodes have resurfaced through Java and the .NET framework which for some reason caused a stir in the whole development community. I honestly never bought into the hype, but I am old enough to remember the whole story – so I’m probably not the Microsoft demographic anyways. Java hyped their virtual machine opcodes to the point of exhaustion. People really are stupid. Man did they do a number on CEO’s and heads of R&D around the world.
Anyways, end of the story was that Intel and AMD went with it and did some optimizations that could help bytecodes run faster. The stack was optimized with Java, because let’s face it – it is the proverbial assault on the hardware. And the cache was expanded on command from the emper.. eh, Microsoft. Also (if I remember correctly) the “jump to pointer” and various branch instructions were made to execute faster. I remember reading about this in Dr. Dobbs Journal and Microsoft Developer Magazine; granted it was a few years ago. What was interesting is the symbiotic relationship that exists between Intel and Microsoft, I really didn’t know just how closely knit these guys were.
Either way, bytecodes in 2017 is capable of a lot more than they ever were on 16-bit and early 32-bit systems. A cpu like Intel i5 or i7 will chew through bytecodes like a warm knife on butter. It depends on how you orchestrate the opcodes and how much work you delegate to the various instructions.
Modeled instructions
Bytecodes are cool but they have to be modeled right, or its all going to end up as a bloated, slow and limited system. You don’t want to be to low-level, otherwise what is the point of bytecodes? Bytecodes should be a part of a bigger picture, one that could some day be modeled using FPGA’s for instance.
The LDef format is very flexible. Each instruction is ultimately a single 32-bit longword (4 bytes) where each byte holds key information about the command, what data is forward in the cache and how it should be read.
The byte organization is:
- 0 – Actual opcode
- 1 – Instruction layout
Depending on the instruction layout, the next two bytes can hold different values. The instruction layout is a simple value that defines how the data for the instruction is passed.
- Constant to register
- Variable to register
- Register to register
- Register to variable
- Register to stack
- Stack to register
- Variable to variable
- Constant to variable
- Stack to variable
- Program counter (PC) to register
- Register to Program counter
- ED (exception data) to register
- Register to exception-data
As you can probably work out from the information here, this list hints to some archetectual features. Variables are first class citizens in LDef, they are allocated, managed and released using instructions. Constants can be either automatically handled and references by id (a resource chunk is linked to the class binary) or “in place” and compiled directly into the assembly as part of the instruction. For example
load R[0], "this is a test"
This line of code will take the constant “this is a test” and move it into register #0. You can choose to have the text-data stored as a proper resource which is appended to the compiled bytecode (all classes and modules have a resource chunk) or just compile “as is” and have the data read directly. The first option is faster and something you can adjust with compiler optimization options. The second option is easier to work with when you debug since you can see the data directly as a part of the debug memory dump.
And last but not least there are registers. 32 of them in number (so for the low-level coders out there you should have few limitations with regards to register mapping). All operations (like divide, multiply etc) operate on registers only. So to multiply two variables they first have to be moved into registers and the multiplication is executed there – then you can move the result to a variable afterwards.

LDef assembly code. Simple but extremely effective
The reason registers is used in my runtime system – is because you will not be able to model a FPGA with high-level concepts like “variables” should someone every try to implement this as hardware. Things like registers however is very easy to model and how actual processors work. You move things from memory into a cpu register, perform an action, and then move the result back into memory.
This is where Java made a terrible mistake. They move all data onto the stack and then call the operation. This simplifies execution of instructions since there is never any registers to keep track of, but it just murders stack-space and renders Java useless on mobile devices. The reason Google threw out classical Java (e.g Java as bytecodes) is due to this fact (and more). After the first android devices came out they quickly switched to a native compiler – because Java was too slow, to power-hungry and required too much memory (especially stack space) to function properly. Battery life was close to useless and the only way to save Java was to go native. Which is laughable because the entire point of Java was mobility, “compile once run everywhere” — yeah well, that didn’t turn out to well did it 😀
Dot net improved on this by adding a “load resource” type instruction, where each method will load in the constant data by number – and they are loaded into pre-defined slots (the variables you have used naturally). Then you can execute operations in typical “A + B to C” style (actually all of that is omitted since the compiler already knows both A, B and C). This is much more stack friendly and places performance penalty on the common language runtime (CLR).
Sadly Microsoft’s platform, like everything Microsoft does, requires a pretty large infrastructure. It’s not simple, elegant and fast – it’s more monolithic, massive and resource hungry. You don’t see .net being the first thing ported to a new platform. You typically see GCC followed by Freepascal.
LDef takes the bytecode architecture one step further. On assembly level you reference data using identifiers just like .net, and each instruction is naturally executed by the runtime-engine – but data handling is kept within the virtual realm. You are expected to use the registers as temporary holding slots for your information. And no operations are ever done directly on a variable.
The benefit of this is:
- Better payload balancing
- Easier to JIT since the architecture is closer to real assembly
- Retains important aspects of how real hardware works (with FPGA in mind)
So there are good reasons for the standard, all of them very good.
C like intermediate language
With assembler so clearly defined you would expect assembly to be the way you work. In essence that what you do, but since OOP is built into the system and there are structures you are expected to populate — structures that would be tedious to do in raw unbridled assembler, I have opted for a C++ inspired intermediate language.

The LDEF assembler kitchen sink
You would half expect me to implement pascal, but truth be told pascal parsing is more complex than C parsing, and C allows you to recycle parsers more easily, so dealing with sub structures and nested regions is less maintainance and easier to write code for.
So there is no spesific reason why I picked C++ as a intermediate language. I would prefer pascal but I also think it would cause a lot of confusion since object pascal will be the prime citizen of LDef languages. My other language, N++ also used curley brackets so I’m honestly not strict about what syntax people prefer.
Intermediate language features supported are:
- Class declarations
- Struct declarations
- Parameter to register mapping
- Before mehod code (enter)
- After method code (leave)
- Alloc section for class fields
- Alloc section for method variables
The before and after code for methods is very handy. They allow you to define code that should execute before the actual procedure. On a higher level when designing a new language, this is where you would implement custom allocation, parameter testing etc.
So if you call this method:
function testcode() {
enter {
writeln("this is called before the method entry");
}
leave {
writeln("this is called after the method exits");
}
writeln("this is the method body");
}
Results in the following output:
this is called before the method entry this is the method body this is called after the method exits
When you work with designing your language, you eventually.
Truly portable
Now I have no aspirations in going into competition with neither Oracle, Microsoft or anyone in between. Like most geeks I do things I find interesting and enjoy working within a field of computing that is stimulating and personally rewarding.
Programming languages is an area where things havent really changed that much since the golden 80s. Sure we have gotten a ton of fancy new software, and the way people use languages has changed – but at the end of the day the languages we use havent really changed that much.
JavaScript is probably the only language that came out of the blue and took the world by storm, but that is due to the central role the browser holds for the internet. I sincerely doubt JavaScript would even have made a dent in the market otherwise.
LDef is the type of toolkit that can change all this. It’s not just another language, and it’s not just another bytecode engine. A lot of thought has gone into its architecture, not just notions of “how can we do this or that”, but big ideas about the future of computing and how IOT will sculpt the market within 5-8 years. And the changes will be permanent and irrevocable.
Being able to define new languages will be utmost important in the decade ahead. We don’t even know the landscape yet but we can extrapolate some ideas based on where technology is going. All of it in broad strokes of course, but still – there are some fundamental facts about computers that the timeless and havent aged a day. It’s like mathematics, the Pythagorean theorem may be 2500 years old but it’s just as valid today as it was back then. Principles never die.
I took the example of a game engine at the start of this article. That might have been a poor choice for some, but hopefully the general reader got the message: the nature of control requires articulation. Regardless if you are coding an invoice system or a game engine, factors like time, portability and ease of use will be just as valid.
There is also automation to keep your eye on. While most of it is just media hype at this point, there will be some form of AI automation. The media always exaggerates things, so I think we can safely disregard a walking, self-aware Terminator type robot replacing you at work. In my view you can disregard as much as 80% of what the media talks about (regardless of topic). But some industries will see wast improvement from automation. The oil and gas sector are the most obvious. A the moment security is as good as humans can make them – which means it is flawed and something goes wrong every day around the globe. But smart pumping stations and clever pressure measurements and handling will make a huge difference for the people who work with oil. And safer oil pipelines means lives saved and better environmental control.
The question is, how do we describe programs 20 years from now? Is our current tools up for the reality of IOT and billions of connected devices? Do we even have a language that runs equally well as a 1000 instance server-cluster as it would as a stand alone program on your desktop? When you start to look into parallel computing and multi-cluster data processing farms – languages like C# and C++ makes little sense. Node.js is close, very close, but dealing with all the callbacks and odd limitations of JavaScript is tedious (which is why we created Smart Pascal to begin with).
The future needs new things. And for that to happen we first need tools to create them. Which is where my passion is.
Node, native and beyond
When people create compilers and programming languages they often do so for a reason. It could be that their own tools are lacking (which was my initial motivation), or that they have thought of a better way to achieve something; the reasons can be many. In Microsofts case it was revenge and spite, since they were unsuccessful in stealing Java away from Sun Microsystems (Oracle now owns Java).
LDef binaries are fairly straight forward. The less fluff the better
Point is, you implement your idea using the language you know – on the platform you normally use. So for me that is object pascal on windows. I’m writing object pascal because while the native compiler and runtime is written in Delphi – it is made to compile under Freepascal for Linux and OS X.
But the primary work is done in Smart Pascal and compiled to JavaScript for node.js. So the native part is actually a back-port from Smart. And there is a good reason I’m doing it this way.
First of all I wanted a runtime and compiler system that would require very little to run. Node.js has grown fat in features over the past couple of years – but out of the box node.js is fast, portable and available almost anywhere these days. You can write some damn fast and scalable cloud servers with node (and with fast i mean FAST, as in handling thousands of online gamers all playing complex first person worlds) and you can also write some stable and rock solid system services.
Node is turning into a jack of all trades, capable of scaling and clustering way beyond what native software can do. Netflix actually re-wrote their entire service stack using node back in 2014. The old C++ and ASP approach was not able to handle the payload. And every time they did a small change it took 45 minutes to compile and get a binary to test. So yeah, node.js makes so much more sense when you start looking a big-data!
So I wanted to write LDef in a way that made it portable and easy to implement. Regardless of platform, language and features. Out of the box JavaScript is pretty naked stuff and the most advanced high-level feature LDef uses is buffers to deal with memory. everything else is forced to be simple and straight forward. No huge architecture or global system services, just a small and fast runtime and your binaries. And that’s all you need to run your compiled applications.
Ultimately, LDef will be written in LDef itself and compile itself. Needing only a small executable stub to be ported to a new platform. Most of mono C# for Linux is written in C# itself – again making it super easy to move mono between distros and operating systems. You can’t do that with the Visual Studio, at least not until Microsoft wants you to. Neither would you expect that from Apple XCode. Just saying.
The only way to achieve the same portability that mono, freepascal and C/C++ has to offer, is naturally to design the system as such from the beginning. Keep it simple, avoid (operatingsystem) globalization at all cost, and never-ever use platform bound APIs except in the runtime. Be Posix but for everything!
Current state of standard and licensing
The standard is currently being documented and a lot of work has been done in this department already. But it’s a huge project to document since it covers not only LDEF as a high-level toolkit, but stretches from the compiler to the source-code it is designed to compile to the very binary output. The standard documentation is close to a book at this stage, but that’s the way it has to be to ensure every part is understood correctly.
But the question most people have is often “how are you licensing this?”.
Well, I really want LDEF to be a free standard. However, to protect it against hijacking and abuse – a license must be obtained for financial entities (as in companies) using the LDEF toolkit and standard in commercial products.
I think the way Unreal software handles their open-source business is a great example of how things should be done. They never charge the little guy or the Indie developer – until they are successful enough to afford it. So once sales hits a defined sum, you are expected to pay a small percentage in royalties. Which is only fair since Unreal engine is central to the software to begin with.
So LDef is open source, free to use for all types of projects (with an obligation to pay a 3% royalty for commercial products that exceeds $4999 in revenue). Emphasis is on open source development. As long as the financial obligations by companies and developers using LDEF to create successful products is respected, only creativity sets the limit.
If you use LDEF to create a successful product where you make 50.000 NKR (roughly USD 5000) you are legally bound to pay 3% of your product revenue monthly for the duration of the product. Which is extremely little (3% of $5000 is $150 which is a lot less than you would pay for a Delphi license, the latter costing between upwards of USD 3000).

You must be logged in to post a comment.