Archive
Quartex Pascal: Dynamic JS structures
If you work closely with JavaScript, it’s important to be able to approach JS in way that is both familiar to Object Pascal developers, yet compatible with the underlying reality of JavaScript. We want to do as much as possible in Object Pascal, but in order to achieve that – we first need to learn how to properly integrate with JavaScript without loss of fidelity and performance.

Object Pascal is strictly typed and linear in execution, which has a lot of benefits for a traditional developer. But JavaScript is the exact opposite and thrives on untyped data and async execution. It is only recently that concepts such as classes have appeared in JavaScript, and they have little in common with traditional C/C++ or Pascal classes.
In order to make JavaScript’s ad-hoc data structures endurable from Object Pascal, we needed to introduce something new. And that is what anonymous classes is all about.
What on earth are anonymous classes?
In short, an anonymous class is essentially an object instance that is created “ad-hoc” where you define it. Please keep in mind that the class we are talking about here is not a pascal class type, but a JavaScript object instance. So in Delphi terms this is closer to a managed record than an object instance.
The syntax could not be simpler:

The above snippet will create a JavaScript object containing the field structure we have defined between the class and end keywords. The reason for this somewhat spartan approach is because JS expects these types of structures as parameters practically everywhere – and we wanted to keep things as short as possible. Having to pre-define a type would defeat the entire purpose, and a constructor call or new keyword would just get in the way.
You can omit defining datatypes for the fields (optional), as long as the data is compatible with whatever the DOM is expecting it will work just fine.
To show you how elegantly this solves integration -let’s deal with a real-life example, like the HTML element.animate() method.
Parameters simplified
Before we look at the code, keep in mind that all QTX widgets (visual controls) manages a underlying HTML element for the duration of it’s life-cycle. Meaning that the widget code will create, maintain and ultimately destroy the HTML element that visually represent it. Just like the VCL does for WinAPI controls.
The default element for TQTXWidget is the <DIV> element. Different widgets override this and create other browser element types. You can access the element directly via the Handle property, which is a direct reference to the element managed by the widget code. This is the exact same approach that the Delphi VCL uses, so it should be second nature to Delphi and Freepascal developers.
So when you want to work directly with the element, you can either just use the Handle directly, or typecast it to JElement for simplicity (all DOM types are prefixed with J in our RTL).
Since THandle derives from variant, you dont really need to typecast; you can just write the methodname directly, a bit like how you can call COM methods through a Delphi variant reference. In such a case you have to make sure the method or property is spelled correctly (JavaScript is case sensitive) and that the parameters match.
Both of these syntaxes can be used, just like COM:
- self.Handle[“someMethod”](param1, param2);
- self.Handle.someMethod(p1, p2);
To make things easier I suggest you typecast to JElement, so that you get the benefit of code suggestion and parameter hints. The JElement definition is a bit spartan, I only defined what I needed to write the RTL. I will re-visit these types when I have more time and define them completely. The animate() definition will be there in the update this weekend.

But let’s get back to the example, namely the Element.animate() method! It is defined as such:
element.animate(keyframes[]; options);
In Object Pascal syntax it would look like this:
procedure JElement.animate(keyframes: array of variant; options: variant);
If we look at the developer documentation for this method, we see that the “array of keyframe” (first parameter) expects an array of keyframe structures. The way animation works in a browser, is that you define how an element should look or be positioned when an animation starts, and then how it should look or be positioned when the animation ends. Based on how long the animation runs the browser figures out whatever frames should appear between keyframes.
The simplest animation would have a start and stop keyframe, but you can define as many keyframes as you like. This type of animation is called “tweening”. The QTX runtime library actually implements it’s own tweening (qtx.dom.tween.pas) engine, which will be used as a fallback mechanism for browsers that dont support the animate() method. If you dont quite understand how tweening works, you should open up that unit and learn from it.
The challenge for us, is that you can animate more or less every css property HTML5 supports, which means it becomes impossible for us to define a traditional object pascal type for the keyframe parameter. At least not without boxing developers in or adding some overhead.
Unassigned is important
The thing about JS and data structure parameters is -that you should only name and assign values to properties you actually use. Most JS framework when dealing with structures, will just check if a named field exist, and further if it’s value is unassigned or not. Think variant programming in Delphi here and how null does not mean empty, only unassigned means empty.
So whenever we work with such structures, we must never declare fields we dont actually use and absolutely not assign values to them. Doing so will wreak havoc, because the browser would interpret this the wrong way and apply them, even if you just set them to null (!). And that is why we should not define a JKeyframe type because a strict type could yield unexpected behavior.
Let’s look at how JavaScript developers would call the element.animate() method:

This is where anonymous classes comes in and saves the day for us. Since it is “anonymous” that means there is no type declaration or consequent field checking involved. You essentially type the object structure ad-hoc where you need it – with the values you need.
Here is how you would call the element.animate() method from Quartex Pascal:

Use it when needed
The usefulness of anonymous classes should be self-evident to everyone:
- First, we get to co-exist with JavaScript without having to manually construct our parameters before calling. It strikes a compromise between structure and efficiency that is optimal imo.
- Secondly, these class instances are thin and requires less memory than a TObject based instance. There simply is no overhead and the generated code is 1:1 Javascript with no magic infrastructure.
- Third, we can read and use standard HTML documentation without having to jump through hoops or manually construct JavaScript object parameters. No asm section is needed.
- Fourth, a JS object is a JSON object by nature, anonymous classes can be used when calling methods that expects a JSON object — and you can serialize / parse them on the spot (!). This affects a lot of scenarios, especially working with REST calls
The only downside is that you cannot inherit from these structures since they are defined ad-hoc where you use them. This kind of definition was tailor made for integrating with JS, like many other aspects of the DWS / QTX dialect.
You can use them in your pascal widget code too, there is nothing stopping you. However, if the data is uniform and has a fixed structure (and initialization of fields is not an issue, like it is under most JS frameworks), you might want to consider a Record type or JObject based class definition to save yourself potential naming errors. The downside of anonymous structures and named fields is that JavaScript is case sensitive. This means that even a single letter typo can be enough to cause havoc in your code. And you end up searching for hours to find that one place where you used an uppercase rather than a lowercase.
Traditional object pascal declarations saves you from this through strict typing and uniform naming. That is one of the benefits of compiling from object pascal to JS, namely that you dont have to deal with all of that. But when working with raw JS calls, much like you would call WinAPI directly under the VCL, data structures have to meet standards.
What about inheritance and more complex structures?
For inheritance (read: building up complex JS structures) where TObject cannot be used, you can base a class-type on JObject – which you declare more or less as a traditional object pascal class:

To create an object instance of a JObject based class, you use the new keyword:
var myObj := new JMyStuff2();
Another note is about obfuscation. Anonymous classes and JObject derived classes survives obfuscation. The compiler makes sure the member names of such classes are not ruined by the obfuscator (see build options). Obfuscation is basically scrambling the JS so it becomes unreadable and more compact, to protect intellectual property. It’s important to keep this in mind. All TObject members are renamed and scrambled, which protects their naming and logic – but this makes them unsuitable as parameters to JS frameworks which expects fields to be named according to a scheme. TObject also has a VMT which means you dont want to use it for parameters to begin with.
To sum up: Use anonymous classes for ad-hoc structured parameters. Or, inherit your traditional classes from JObject if you need strict typing and pseudo inheritance. These are both compatible with standard JavaScript.
QTX is about balance between these two realities. You have the rigid, strict and traditional Object Pascal world in one hand– and the flamboyant, ad-hoc world of JavaScript in the other. Within the QTX dialect we (read: Eric Grange and myself) tried to forge a compromise that brings the best of both languages together. Most of the modern features that DWS and QTX supports came out of our initial exploration back in 2010 to 2012. The first year we would debate features almost daily, trying new things and thinking about stuff we could adopt from other languages that works well with pascal. We had a great time and (imo) came up with a dialect that is excellent for web development.
Notes
This article was first posted on my Patreon project website. If you find QTX interesting, please consider backing the project. You can visit the Patreon website here: www.patreon.com/quartexnow, and you can visit the official website to read more about Quartex Pascal in general here: www.quartexdeveloper.com.
Quartex Pascal: Status and progress
It’s been a while since I have written anything on my personal blog. Truth is that between my day-job and QTX development in my spare time, there is not a lot of room to maintain another blog. The Quartex Pascal project (QTX) is coming along nicely, and we have both the Patreon website and our official website, as well as a fairly busy Facebook group.
If you want to see what can be achieved with Quartex Pascal, check out this video on YouTube demoing the desktop project type:
Some background
If you haven’t followed my blog over the past 5-6 years, I started implementing a web desktop system a few years back, that would do for JavaScript apps what Windows did for native applications. This was first implemented for kiosk systems (early prototype) but later I implemented a prototype that was fully windowed (meaning, that hosted applications would appear in their own windows, much like on MacOS or Microsoft Windows) and supported a real filesystem. The filesystems were implemented in typical driver style, where you would inherit out from a base-class and implement the specifics for whatever file-source you needed. Out of the box I supported a node.js back-end filesystem service, Dropbox and Zip file system.

This was no mere ‘mock’ desktop. Hosted apps would connect to the desktop, which in turn exposed API’s both in the desktop code itself, and server-side, which the hosted app could invoke. Things like displaying a file-open dialog, enumerating files, reading and writing files etc — was all done properly through async API calls from the hosted app, and the desktop. Hosted apps are isolated in an IFrame context, complete with heavy security restrictions.
This project was sadly put on hold after about a year, as it became clear that we needed better tooling (read: compiler and RTL) to finish it. We had exhausted the initial development system and I saw no other option but to create a new one. So for the past 3 years I have been busy creating Quartex Pascal. A toolchain (compiler, IDE and RTL) that allow you to write Object Pascal, but compile to raw, kick-ass JavaScript. And the resulting code is way ahead of the competition in terms of speed and features.
Awesome progress
Quartex Pascal has grown far beyond what we initially planned (with ‘we’ I mean myself and the backers I have been lucky enough to converse with during the development phase). Here are some of the highlights that are now in place:

- Package support for visual components [and units in general] is now a reality, so people can write their own HTML5 components and have them registered with the component palette. Support for third party JS frameworks benefits greatly from packages, as you can bundle both the native js files, needed dependencies, and the pascal units that define the components in a single file. Packages are just zip files renamed to *.pkg, no point re-inventing the wheel with yet another magic fileformat.
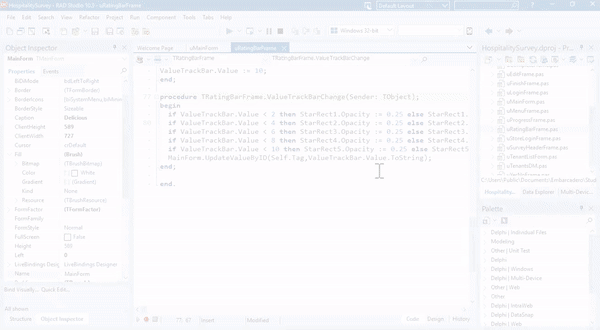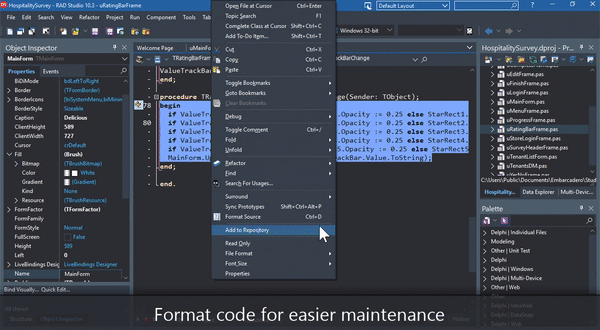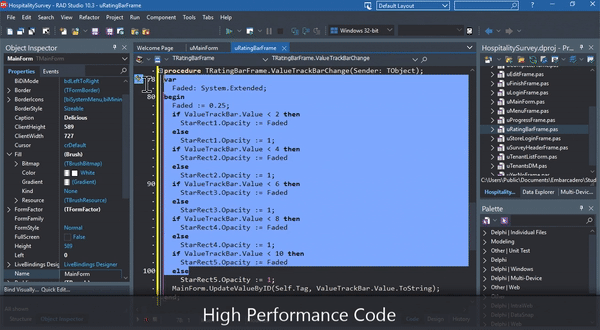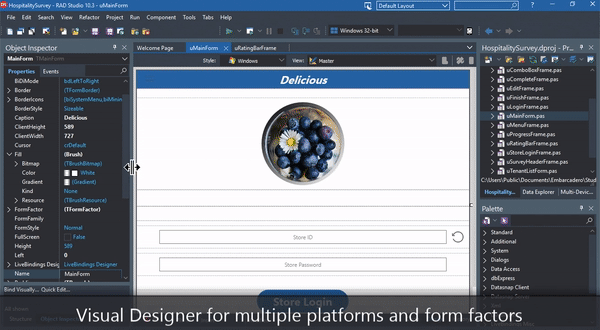
- Drag & Drop components and form designer is likewise a reality now. While I personally rarely use a form designer, it does save a ton of time when doing quick UI designs. HTML5 is not Delphi, so there are more properties that will define the final outcome, such as positionmode and layoutmode. But knowing how those two properties work is more than enough, the rest is very close to what you are used to in Delphi.
- Delegate event support is in place (visually as a part of the inspector / designer page). As you probably know, JS supports two types of events: you have the traditional events which we know and use in Delphi, which is basically a method reference. And then there is the more modern concept of ‘delegates’, where you have an object that represents and event. The latter allows you to bind as many handlers as you wish to any single event, which then fires in the same sequence that they were attached to the delegate. The visual designer only supports delegates. You can use ordinary Delphi events in your own code, and most components expose classical events besides delegates – but the form designer only deals with delegates. Which are super easy to use and the way JavaScript deals with things these days.
- Web worker support, these units are compiled separately since they run in separate processes, and you use the message-port to communicate with the form or application itself. You can use the Ragnarok message framework to implement a protocol where messages are uniform and support attachments (e.g a binary file you want to process, or any other data you need handled).

What is next?
I have a couple of tickets left, but all in all the final ‘big’ ticket is to implement a Ragnarok (message framework) code generator for server-side code. Client side is already there and working. The other tickets are things like polishing, putting js frameworks in packages (so you can drag & drop their components and use them on a form), and polishing minor mistakes and details I might have forgotten here and there.
So if you think TMS is the only game in town, think again 🙂
Quartex Pascal will ship with features and components that will blow your mind.
References
You can visit the Patreon website and become a backer. This gives you access to regular builds. I issue a new build roughly every other weekend.
You can visit the official website, quartexdeveloper.com, and read more in-depth about the project and it’s goals there.
Curious VCL snippet brainfart
I was poking around the VCL system.math unit yesterday when I came across a curious function implementation. Not curious because of complexity, but rather baffling as to why they would implement it like this. While the performance gain in question is insignificant in the great scope of things, the backstory here is that the VCL is full of similarly written code. Code that, when you sum up the penalty on application level, becomes quite considerable.
So while this little snippet is meaningless, it is symptomatic for the maintenance of the VCL these past 15 years. I simply don’t understand why they would let code like this remain when performance improvements are in such high demand.

So what is the problem you ask? Well, “problem” is not the right word for it, baffling is closer to what I feel when I look at these functions. So let me sum up what I see when I look at this code:
- The code allocates two variables for a piece of logic that has absolutely no need for it
- Dividing these two simple expression into separate blocks makes my eyes hurt
In other words, the code that immediately comes to mind for me would be:

If you are pondering why I would use the $B+ (complete Boolean evaluation) compiler switch on this, there is a reason for that. Namely that the compiler wont have to divide the logic into a two piece code-block, and further having to add a branch instruction to exit the block if the first evaluation was false (I know I’m neckbearding this right now).
In short: The code above is actually faster and ensures both expressions are solved on the stack. No variable allocation needed and no adjustment of the stack-page boundary.
Symptomatic?
The snippet above is obviously insignificant when you look at it isolated. It barely justifies writing this text to explain it. But over the past decade the VCL has begun to annoy me a bit, because there are literally thousands of such snippets all over the VCL. Some of you might remember a homebrew project called “the Delphi unit replacement project” from way back? Where some guy took the time to refactor the standard Delphi VCL units (which obviously broke a few laws). It was nothing too elaborate either (no assembler or anything super low-level), just relatively simple refactoring like I demonstrated above, except he did that to every function and procedure in the non-visual scope of the VCL. And to my utter amazement those units provided as much as 30 – 40% performance gain for average applications. In other words, if you recompiled your application using his units, your program could run up to 40% faster.
I honestly did not believe it until I saw it myself.
A lot has been done to improve the VCL in the past 8 years, which is why I find it strange to discover sloppy code like this in a unit literally named “mathematics”. That unit should be optimized to the bone. I mean, just look at what the C/C++ guys are enjoying in their standard libraries, where every inch of the RTL is optimized for performance. The Delphi compiler is just as capable of generating high performance code, but obviously it cant magically convert wasteful code into gold either.
So during lunch yesterday I took 3 minutes to just make sure I was correct. Again, this post is not really about the above function, but rather the sheer volume of such waste in the VCL. I remember when Delphi was the fastest kid on the block, and it just annoys me that – knowing how well Delphi can perform, that eyesores like this openly lingers in the product.

While the potential savings here is nothing in a real-life scenario, and barely worth mentioning — when you suddenly have thousands of such snippets (if not tens of thousands RTL wide), you cant help but think that Embarcadero could put more efforts into general optimization.
I mean, remembering that homebrew project (illegal as it might have been) and seeing as much as 40% performance gain? You cant help wondering how Delphi could perform when given the same attention to detail as the first versions of Delphi received. A 30-40% speed boost would put Delphi en-par with cutting edge C and C++, which is optimized to the absurd. Add LLVM on top of that and it would fly.
It would be fun to see what LLVM would do with that stock InRange() code. I can only speculate but I’m pretty sure it would end up as a simple stack operation with L3 optimization enabled.
</end of brainfart>
QuartexDeveloper.com is now active

It’s taken a while but Quartex Pascal now has it’s own website and forum. You can visit QuartexDeveveloper.com and check it out.
The SSL certificates are being applied within 72hrs according to the host, so don’t be alarmed that it shows up under HTTP rather than HTTPS right now – that is just temporary.
Up until now we have operated with a mix of donations and Patreon to help fund the project, but obviously that model doesn’t scale very well. After some debate and polls on the Facebook group I have landed on a new model.
Funding and access model
Starting with the release of version 1.0, which is just around the corner – the model will be as such:
- Backing and support will be handled solely through Patreon
- Facebook group will become open for all
- Patreon tiers will be modified to reflect new model
- Main activity and news will shift to our website, quartexdeveloper.com
- Community build will be available from our website
- Commercial license will also be available from our website
So to sum up, the following 3 options are available:
- Back the project on Patreon, full access to the latest and greatest 24/7
- Community edition, free for educational institutions and open-source projects (non commercial)
- Commercial license is for those that don’t want to back the project on a monthly basis, but instead use the community edition in a professional capacity for commercial work.
With the community edition available, why should anyone bother to back the project you might ask? Well, the public builds will by consequence be behind the latest, bleeding edge builds since the community edition is only updated on minor or major version increments (e.g. when version changes from 1.0 to 1.1). Users who back the project via Patreon will have instant access to new documentation, new packages with visual components, new project templates, RTL fixes and patches as they are released. These things will eventually trickle down to the community edition through version increments, but there is a natural delay involved.

This is how most modern crowd funded projects operate, with LTS builds (long term support) easily available while the latest cutting edge builds are backers only. Documentation, fixes and updates to components, new component packages, hotfixes and so on – is the incentive for backing the project.
This is the only way to keep the ball rolling without a major company backing day to day development, we have to get creative and work with what we got. Projects like Mono C# had the luxury of two major Linux distribution companies backing them, enabling Miguel de Icaza to work full time on the codebase. I must admit I was hoping Embarcadero would have stepped in by now, but either way we will get it done.

Onwards!
Auto register classes
This is something I wrote back when Attributes was sort of new to Delphi, but it’s a neat example of how custom attributes can simplify your code. It would actually be a nice candidate for addition to the VCL.
In short: If you are serializing objects to JSon, you probably know that Delphi can only re-create those objects if it knows the class type (or if you manually provide the class during parsing). This means that you end up writing an implementation section where you manually call RegisterClass() for each of the class types you use.

While this is not problematic or difficult, it’s one of those chores that is perfect for attributes. So instead of having to write an initialization section on unit level, you can just attach a [ClassRegister] attribute, and it’s automatically registered for you when the unit is loaded into memory.
Here is the unit, feel free to use it and rename it to whatever you like:
unit quartex.util.register;
interface
type
///<summary>
///<para>The [ClassRegister] attribute registers the attached class
/// into Delphi's internal class registry. This is the same as calling
/// RegisterClass manually during unit initialization, except it's
/// simpler and more elegant.</para>
///<code>
///type
/// [ClassRegister]
/// TSomeClass = class(TPersistent)
/// end;
///</code>
///</summary>
ClassRegister = class(TCustomAttribute)
end;
implementation
uses
System.Rtti, System.TypInfo, System.Classes;
// This procedure walks through all classtypes and isolates
// those with our TAutoRegister attribute.
// It then locates the actual classtype and registeres it
// with Delphi's internal persistence layer
procedure ProcessAutoRegisterAttributes;
var
ctx : TRttiContext;
typ : TRttiType;
attr : TCustomAttribute;
lRealType: TClass;
lAccess: PTypeData;
begin
ctx := TRttiContext.Create();
try
for typ in ctx.GetTypes() do
begin
if typ.TypeKind = tkClass then
begin
for attr in typ.GetAttributes() do
begin
if attr is ClassRegister then
begin
lAccess := GetTypeData(typ.Handle);
if lAccess <> nil then
begin
lRealType := lAccess^.ClassType;
if lRealType <> nil then
begin
if lRealType.InheritsFrom(TPersistent)
or lRealType.InheritsFrom(TInterfacedPersistent) then
RegisterClass( TPersistentClass(lRealType) );
end;
break;
end;
end;
end;
end;
end;
finally
ctx.Free();
end;
end;
// We want to register all the classes decorated with our
// attribute when this unit is loaded into memory. This process is
// ultimately very quick since it's all pointer material.
Initialization
begin
ProcessAutoRegisterAttributes;
end;
end.Quartex Pascal: Nearing completion
When developers talk about web development they usually mean creating web pages with the tools common for the web sphere. Web designer software is abundantly available online, from single-click page wizards to more ad-hoc, old school HTML / JavaScript editors. If there is something the world don’t need more of, It’s one-click website solutions.

One challenge that haven’t been addressed until recent times in the web sphere, is that of programming language. JavaScript is a fun language, but it was never really designed for large-scale application development. As websites become more and more elaborate, the need for traditional programming languages and features started to surface. In many ways the past 15 years of browser evolution, has been all about JavaScript catching up with the needs of developers.
But are we really limited to JavaScript?
When it comes to language and web technology, it was C/C++ that became the second language of the internet via the introduction of Asm.js and eventually Webassembly. It took a long time for other languages to adopt the Webassembly binary format as a target. WebAssembly is a bytecode binary format consisting of low-level instructions, much like assembly for x86 processors. These instructions are converted into real machine code by the browser (via a process called JIT compilation), and as a result the performance of Webassembly is close to native code. Having said that, Webassembly comes with its own set of restrictions and challenges, especially when it comes to manipulating the DOM (the document object model, the elements that makes up a HTML document).
The Quartex Way
Back in 2010 I had a novel idea with regards to languages: what if we translate Delphi code on source level, and emit JavaScript instead? At the time there was no such thing as webassembly, and the closest thing to a binary format was Macromedia Flash. Without rehashing the story, I teamed up with Eric Grange from Creative IT in France, the maintainer of Delphi Web Script, and the end result was a compiler that would parse Object Pascal code, construct an AST (abstract symbol tree) which is a model that represents the entire program, and further convert that into optimized JavaScript.
In order for such a system to work properly, a whole new RTL (runtime-library) had to be created. All the functions, procedures and classes that Delphi provides would not magically compile to JavaScript. So someone had to sit down and implement classes and features that made sense for the browser, from TComponent all the way up to TCustomControl – but in a way that is compatible with HTML.

It is out of this work that the Quartex Framework came into being, as a personal research and development framework dealing with web technology. Back in 2014 it was just a utility library, and it remained as such until 2019 when it became a fully functional RTL in its own right. An RTL with a wingspan from low-level binary data, all the way up to visual components and database connectivity. In 2020 it expanded to Node.js, which is a JavaScript scripting-host used to write servers and services. The Quartex framework as now a full stack RTL that radically cuts down on development time needed when writing websites, mobile applications or server technology.
The Quartex IDE
Delphi has a wonderful IDE that has been polished and evolved over almost 2 decades. It is possible to introduce new compilers and third party technology into that IDE, but Delphi is limited to native technology. The only way to integrate QTX with Delphi, would be to mimic the VCL or FMX in its entirety, so that class-names match and the form design files could be read and used by the Quartex Compiler.
While such a project would probably be easier, it also meant a massive compromise in terms of features and performance. As a native development system Delphi does things in a very specific way, and if I forced JavaScript and HTML to abide by those rules – we would lose the dynamic and flamboyant aspects of HTML5 and JavaScript. The performance would also be poor since the VCL (and consequently LCL) was never written for the browser or Node.js. A test I did on performance, comparing QTX compiled code with TMS compiled code demonstrates my point. TMS populates a listbox with roughly 1000 items in 2 seconds. QTX populates the same listbox with 20.000 items in 1.8 seconds.
The only reasonable way forward was to implement a separate IDE, one that dealt with web technology exclusively. And what better language to write such a system in than Delphi itself? I was actually thinking that Embarcadero might want to rekindle their HTML5 Builder, and let me do my magic on it. Quartex Pascal is in many ways what HTML5 Builder should have been, and it’s just getting started.

Writing an IDE is a massive undertaking. It covers technologies such as code suggestion, form and container designer, communication protocol design, license management – and much, much more. The IDE has been worked on every weekend for a year, and the results are solid.
What is important with an IDE like this, is that it represents a broad foundation for further development. It is written to be highly modular, with everything neatly isolated in classes. If a particular feature requires adjustment, then refactoring that particular module is a straightforward task. Large applications have a tendency to become a mesh of spaghetti that only the original developer understands, something I have worked very hard to avoid. The source-code is available for backers on Patreon.

Server Side Programming
Node.js is a scripting host based on Google’s V8 JavaScript engine, which runs outside the browser. It is designed to run from the command-line (read: standard scripting host) and gives developers all the features you expect from a native program, like raw file access, multi threading (read: Node operates with multi processes), servers and sockets, third party libraries and much more.
Being able to write both client and server from the same development system, a so called “full stack” development environment, is a great boon and opens up for deployment on enterprise level.

But being able to communicate across services and servers means that the IDE had to provide the tools for async network programming. Working with async code is not hard, but it can be difficult if your codebase does not take height for it.
To help simplify communication between servers, services or clients (read: browser and server, or locally as inter process communication) I wrote the Ragnarok message framework. The IDE now has a visual protocol designer which makes it extremely easy to design messages and complex datatypes that is used when communicating. The protocol designer takes your design and generates ready-to-use classes and units.

Object Pascal as a web language
You might think that object pascal with its rigid rules and pure logic is too stiff for web development. It turns out that this was exactly what the browser needed, as a solid anchor to the otherwise “anything goes” reality of JavaScript. Eric Grange made a lot of changes to the dialect which allows Quartex Pascal to interface more easily with JS, such as partial classes, external classes, static (in the C++ / C# meaning of the word), support for lambdas, inline variables, anonymous procedures, records and classes – and finally support for the async and await keywords when working with promises.

Object Pascal brings a clarity to web development that JavaScript and TypeScript simply lacks. It also introduces normal inheritance (like C/C++ and Delphi has), with abstract and virtual members. When you combine this with partial classes, you have a dialect that is extremely productive, and that takes on node.js and Javascript on its own terms.
Come join the fun
The Quartex Pascal project is nearing completion. It is not finished just yet, but I am aiming for a release of version 1.0 before xmas. Quartex Pascal is based on Patreon backing, which means those that back the project and contribute financially enjoys weekly builds and working closer with the author on shaping the system. Premium backers also have access to the source-code, with rights to modify and use the system for whatever they like, providing the no-compete clause is respected.
If you find Quartex Pascal interesting – why not become a backer?
Quartex Pascal will be free for schools and educational institutions, as well as for students, non-profit organizations and open-source development. For commercial use a symbolic fee of $300 is needed. The system is licensed as shareware in order to avoid an avalanche of clones, which can quickly kill a project.

HTMLComponents for Delphi, a closer look
For a while now I have been paying attention to Alexander Sviridenkov’s components for Delphi. First of all because Delphi doesn’t really have that many options when dealing with HTML beyond embedding the classical browsers (Chromium, Firefox or Edge); And while Dave Baldwin’s work has served the community well in the past, TFrameBrowser is 20 years old. So there is definitively room for improvement.
Secondly, in my work with Quartex Pascal, a system that compiles Object Pascal to JavaScript for HTML5, being able to work with HTML and render HTML easily from my IDE is obviously interesting. The form designer in particular could benefit from showing “live” graphics rather than representative rectangles.

All of that is possible to do with Chromium if you run it in an off-screen capacity, but getting good results is very tricky. Chromium Embedded runs in a separate thread (actually, multiple threads) and sharing video memory, injecting HTML to avoid a full reload — lets just say that a Delphi native component package would make all the difference. Enter HTMLComponents.
Focus on the essentials first
The way that Alexander has proceeded with his components can resemble my own philosophy (or indeed anyone who has been a developer for a while). It’s the kind of work approach you end up with through experience, namely, to start with the basics and make sure that is rock solid (read: focus on the foundation code, that’s what’s going to matter the most. Trust me). It’s so tempting to run off on a tangent, adding more and more functionality – typically visually pleasing stuff, but as mature developers will know, if you go down that path what you end up with is a very expensive mess.

Thankfully, Alexander has gone about his work in an orderly, no-nonsense way. He began with the HTML parser, making sure that was flexible, compliant and delivered great performance (over 100 Mb a second!). Then he moved on to the CSS part of the equation and implemented a high performance styling engine. The reason I outline this is because I don’t think people fully grasp the amount of work involved. We think of HTML as a simple tag based format, but the sheer infrastructure you need to represent modern HTML properly is enormous. There is a reason Delphi component vendors shy away from this task. Thankfully Alexander is not one of them.
Scripting?
Next we have the scripting aspect. And here is the twist, if we can call it that. HTMLComponents is not written to be a browser. It is written to enable you to render HTML5 at high speed within a native application, including CSS animations and Tweening (a technique made popular by Apple. Like sliding forms or bouncing swipe behavior).
In other words, if you are expecting to find a browser, something like Dave Baldwin’s now ancient TFrameBrowser, then you should probably look to the new TEdgeBrowser component from Embarcadero. So JavaScript is not yet natively supported. HTMLComponents falls into the category of a UI presentation framework more than a browser.
If however, like myself, you want to handle presenting HTML5, PDF, RTF and Word documents without a ton of dependencies (Chromium adds 150Mb worth of libraries you need to ship), provide your users with a compliant HTML WYSIWYG Editor – and also deliver those fancy animated UI elements – then you are going to love HTMLComponents.
I should mention that HTMLComponents has its own scripting engine, but it’s not JavaScript. But for those situations where a script is needed, you can tap into the scripting engine if you like. Or deal with everything natively. It’s your choice.
Document editor

The reason I mentioned Alexander’s architecture and how his codebase has evolved, is because a high performance document rendering engine can be very useful for a variety of tasks.
One thing is rendering HTML5 with all the bells and whistles that entails, but what about RTF? What about Word documents? What about PDF documents? Once you have a rock solid engine capable of representing HTML5, the next logical step is to branch out and work with the other formats of our times. And that is just what Alexander did.
But before we look at those features, let’s have a peek at what components you get.
As you can see from the picture above, HTMLComponents is not just about drawing HTML. Being able to represent HTML is useful in a variety of situations since it simplifies visual feedback that would otherwise be very time consuming to implement. So instead of limiting that power to a single control, HTMLComponents come with common controls that have been infused with superior graphical powers.

The most powerful component in the above list is without a doubt the HTML editor component (also notice that the package installs both standard and DB variations of the various controls). This is quite simply a fully compliant WYSIWYG editor – complete with all the formatting features you expect.
- WYSIWYG editing.
- Does not use IE or other libraries (100% native Delphi code).
- Supports all Delphi versions from Delphi 5 to Delphi 10.4 Sydney.
- Supports Lazarus (Windows/Linux)
- VCL (Win32/64) FMX (Windows / OSX / Android / iOS / Linux)
- Full support for touch-screen devices – gestures, text selection (Windows Tablets/Screens, iOS, Android, OSX)
- Smooth scrolling on Android and iOS.
- Unicode support for Delphi 6 – 2007 (requires TNTUnicode).
- Scalable (High DPI support).
- Live spellchecking and autocorrection (built-in support for Addict).
- Live text styles preview (font family,size, color, background).
- RTF and MS Word DOCX Import on all platforms.
- PDF export on Windows, Android, OSX and iOS.
- DB-Aware version
- Full support for HTML tags and CSS properties.
- Full access from Delphi code to DOM and Styles.
- Images, lists, blocks, font styles
- Tables support
- Print and Print Preview
- Embedded Find dialog, Text search, Document Index generation.
- Copy from/paste to MS Word, browsers and other applications
- Embedded Markdown, Pascal and HTML syntax highlighting.
- HTML-based editor controls (HtFontCombo, HtFontSizeCombo, HtColorCombo, HtTableAddCombo, HtBorderCombo, HtTableBorderCombo)
That is a solid list of features, and did I mention you get full source-code?
HTML empowered controls
If you are looking over the list of controls above and expecting to find something like a browser or viewer control, you won’t find it. The closest thing to a HTML viewer is the panel control (THtPanel). It exposes properties and methods to populate it with HTML (as does all the controls), set what type of scrollbars you need (if any), how to deal with links, images and CSS styling – and then it’s a matter of feeding some HTML into the control.

Obviously controls like THtCombobox have behavior that is dictated by the OS, but you can style the child elements (rows for example) being displayed, the border etc. using the full might of HTML5. And yes, you can apply CSS transitions there as well – which is (excuse my french) bloody spectacular!
I mentioned that HTMLComponents were not designed to be a browser replacement, but rather to make it easier for native developers to tap into the design power and visual feedback that makes HTML5 so productive to use for UIs. Well, once you have set the properties for a panel and given it some HTML -you can do some pretty amazing things!

HTML takes a lot of grunt work out of the equation for you. For example, let’s say you wanted to produce a demo like the one in the picture above (see direct link in the next paragraph). With all the effects, transitions, pictures and displacement elements. Just how much work would that be in traditional Delphi or C++ ?
Note: You can download the Demo application directly, here:
https://delphihtmlcomponents.com/csstransforms.zip
First you would need a panel container for each picture, then a canvas to hold the picture, then you would need to handle the interaction events- and finally access the canvas to draw the many alpha blended transitions (the picture here really doesn’t do the framework credit, you have to see them to fully appreciate the level of detail and performance HTMLComponents delivers). And all of that is before you have new elements flying in from the sides or above, that fades perfectly with the backdrop. All of it working according to a timeline (tweening as its called).
Instead of all that work, having to write a tweening engine, 32 bit alpha-blending DIBs (device independent bitmaps), deal with god knows how much work — you can just deliver some HTML and CSS and let HTMLComponents handle all of it. With zero external dependencies I might add! This is a pure Delphi library. There are no references to external browser controls or anything of the kind. HTMLComponents does exactly what it says on the box – namely to render HTML5 at high speed. And it delivers.
Here is the HTML for one of the pictures with effects in the demo:
<div class="view view-sixth">
<img src="images/13.jpg" />
<div class="mask">
<h2>Hover Style #6</h2>
<p>A wonderful serenity has taken possession ..</p>
<a href="#" class="info">Read More</a>
</div>
</div>
And here is the CSS animation transition code for the same. Please note that the original code contained definitions for IE, Opera, Webkit and Firefox. I removed those for readability:
.view-sixth img {
transition: all 0.4s ease-in-out 0.5s;
}
.view-sixth .mask {
background-color: rgba(146,96,91,0.5);
filter: alpha(opacity=0);
opacity: 0;
transition: all 0.3s ease-in 0.4s;
}
.view-sixth h2 {
filter: alpha(opacity=0);
opacity: 0;
border-bottom: 1px solid rgba(0, 0, 0, 0.3);
background: transparent;
margin: 20px 40px 0px 40px;
transform: scale(10);
transition: all 0.3s ease-in-out 0.1s;
}
.view-sixth p {
filter: alpha(opacity=0);
opacity: 0;
transform: scale(10);
transition: all 0.5s ease-in-out 0.2s;
}
.view-sixth a.info {
filter: alpha(opacity=0);
opacity: 0;
transform: translateY(100px);
transition: all 0.3s ease-in-out 0.1s;
}
.view-sixth:hover .mask {
filter: alpha(opacity=100);
opacity: 1;
transition-delay: 0s;
}
.view-sixth:hover img {
transition-delay: 0s;
}
.view-sixth:hover h2 {
filter: alpha(opacity=100);
opacity: 1;
transform: scale(1);
transition-delay: 0.1s;
}
.view-sixth:hover p {
filter: alpha(opacity=100);
opacity: 1;
transform: scale(1);
transition-delay: 0.2s;
}
.view-sixth:hover a.info {
filter: alpha(opacity=100);
opacity: 1;
transform: translateY(0px);
transition-delay: 0.3s;
}
If CSS is not something you normally don’t bother with, the code above might look complex and alien. But there are tons of websites that have wizards, tutorials and even online editors (!), so if you take the time to read up on how CSS transitions work (they are quite easy), you will knock out some impressive effects in no time.
Once you have built up a collection of such effects, just link it into your Delphi application as a resource if you don’t want external files. Personally I think its a good thing to setup the UI in separate files like that, because then you can update the UI without forcing a binary installation on your customers.
So if we consider the amount of Delphi code we would have to write to deliver the same demo using stock VCL, sum up the cost in hours – and most likely the end result as well (Alexander is exceptionally good at graphical coding), I for one cant imagine why anyone would ignore HTMLComponents. I mean serious, you are not going to beat Alexander’s code here. And why would you waste all that time when you can buy ready to use controls with source-code for such a modest price?
Office formats
I mentioned briefly that with a powerful document rendering engine in place, that the next step of the way would be to cover more formats than just HTML. And this is indeed what Alexander has done.
If you invest in his Add-On Office package for HTMLComponents, you will be able to load and display a variety of document formats. And just like HTMLComponents the code is 100% Delphi and has zero dependencies. There are no COM objects or ActiveX bindings involved. Alexander’s code loads, parses and converts these documents instantly to HTML5, and you can view the results using HTMLComponents or in any modern browser.
Following document formats are supported:
- Rich Text Format (RTF)
- MS Word 6-2007 binary format (DOC)
- MS Word XML document (DOCX)
- MS Power Point binary format (PPT)
- MS Power Point XML format (PPTX)
- MS Excel binary format (XLS)
- MS Excel XML format (XLSX)
- Adobe PDF format (PDF)
- Supercalc format (SXC)
- EPUB (electronic books).
Besides the document conversion classes you also get the following code, which is pretty hard-core and useful:
- EMF/WMF to SVG conversion
- TTF to WOFF conversion
- TTF normalization
- TTF to SVG conversion
- CFF to TTF conversion
- Adobe PostScript to TTF conversion.
For me this was a god-send because I was using Gnostice’s PDF viewer to display the documentation for Quartex Pascal in the IDE. Being able to drop that dependency (and cost!) and use HTMLComponents uniformly throughout the IDE makes for a much smaller codebase – and cleaner code.
Final thoughts
The amount of code you get with HTMLComponents is quite frankly overwhelming. One thing is dealing with a tag based format, but once you throw special effects, transitions and standards into the mix – it quickly becomes a daunting task. But Alexander is delivering one of the best written component packages I have had the pleasure of owning. If you need a fresh UI for your application, be it POS, embedded or desktop utilities – HTMLComponents will significantly reduce the time spent.
I should also underline that HTMLComponents also works on FMX and Mobile devices ( Windows, OS X, Android, iOS and Linux even!). I’m not a huge fan of FMX myself so being able to design my forms using HTML and write event handlers in native Delphi is perfect. FMX has a lot of power, but the level of detail involved can be frustrating. HTMLComponents takes the grunt out of it, so I can focus on application specific tasks rather than doing battle with the UI.
The only thing I would like to see added, is support for JavaScript. HTMLComponents makes it easy for you to intercept scripts and deal with them yourself (HTMLComponents also have a pascal inspired script), but I do hope Alexander takes the time to add Besen (a native Delphi JavaScript engine) as an option. It really is the only thing I can think of in the “should have” apartment. Everything else is already in there.
I have to give HTMLComponents 9 out of 10 stars. It would have scored a perfect 10 with JS support. But this is the highest score I have ever given on my blog, so that’s astronomical. Well done Alexander! I look forward to digging into the office suite in the weeks ahead, and will no doubt revisit this topic in further articles.
Visit Alexander’s website here: https://www.delphihtmlcomponents.com/index.html
Quartex Pascal, status
With Quartex Pascal development at full steam and a dedicated Facebook group for the backers – It’s not often that I post updates here on my blog. One of the benefits of being a backer is that you have direct access to the latest builds, and also that you take part in the dialog on the group.
Be that as it may, here are some of the news happening with Quartex Pascal!
What’s new?
Quite a bit has happened since my last blog post. The IDE is coming together piece by piece, and at the moment i’m focusing on helper functionality for the AST (abstract symbol tree).

As you no doubt know, when a program is compiled it’s first parsed and converted into objects in memory. So every inch of your program becomes an elaborate tree-structure. This structure is what is commonly called the AST – and it is the raw material if you will, that code is generated from. In our case we don’t produce machine code, but rather JavaScript.
As you can imagine such an AST is quite complex. It has to be able to represent all the nuances of Object Pascal, as well as simplify finding information about everything. Every datatype, every record, class or complex structure, every field, expression — it all exists within the AST.
Without code to quickly traverse and work with the AST, things like code suggestions, parameter suggestions, code completion, the much loved ctrl + click — none of those would work. So while boring, it has to be done.
Oh and the mini-map has been re-implemented from scratch, so it’s now fast, accurate and responsive – and it works with mousewheel and keyboard.
Code suggestion
One of features that is bubbling up to the surface right now, is code suggestion. It’s something that we simply take for granted these days, and we dont really consider how much work it is to make. Eric has done a lot to simplify this for DWScript, but you still have to build up the codebase around it. But thankfully that is now largely done, leaving only a bit of styling and focus handling.

Form Files

In the previous build the IDE only recognized unit files (.pas), but in the current version it will check for an accompanying .DFM file. If a form-design file exists, it will open up a form-designer page rather than a pure code page.
The form-designer itself has received a bit of love lately too. Keyboard shortcuts have been added, such as holding down CTRL during a multiple selection — and changes to the layout is signaled back to the IDE and reflected in save-states changing (i.e if you change a form layout, the Save and Save All icon becomes enabled).
The form layout objects (visual widgets) have also been re-worked a bit. We want our DFM file-format to be JSON, so full JSON object persistence has been implemented. The form-designer widgets inherit from TQTXJSONPersistent, making it a literal one-liner to load and save form design.

We do need to wait for the AST explorer code to finish though, before you can start dragging & dropping widgets. Visual controls dont magically appear by themselves. Packages must be registered, and visual controls must likewise be registered with the IDE before they become known to the designer. So once the AST code is finished, we move on to packages – and finally glue the pieces together.
RTL advancements
The RTL has seen just as much changes as the IDE itself, and for good reason. Unlike “other” Web Technology tools, Quartex Pascal has an RTL that supports everything HTML5 has to offer. You are not limited to a static, fixed layout like we are used to under Delphi or Lazarus.
The ability to work with dynamic layout presents some interesting and highly efficient design opportunities. I find myself using the blocking layout model more and more, since it simplifies building up a dynamic UI that scales. Being able to work with different font scales too, like point (pt), as opposed to traditional pixel (px) closes the circle; it makes it possible to implement visual components that can scale it’s content to fit the container. This in turn simplifies writing software that renders well on both Desktop, Mobile and browser.

The changes has been too many to list here, but I have pretty much implemented all the event delegate objects (more to come), tweaked creation speed even further – and added additional polyfill files that ensures that your code works on every browser (a polyfill is a fallback system, so if a browser lacks a feature – the polyfill is used instead).
Application models
Under Quartex Pascal the TApplication object plays an important role, much more than you are used to under Delphi or Lazarus. It is TApplication that is responsible for maintaining your layout – and ultimately how forms are shown.
- If you are writing a mobile application you obviously want your forms to slide into view, just like native applications do on iPhone and Android.
- If you are writing a client-server website solution, you might prefer that forms covers the full width of the browser, with variable height – with the user switching forms by clicking on a toolbar, menu option or link.
- Perhaps you would like the forms to the stacked vertically, so that each form comes into view as the user scrolls downwards – perhaps with some fancy effect, or a static background behind the forms.
- And last but not least, you might prefer that your web application looks and behaves like a Windows desktop application. With multiple windows that can be moved around, a normal menu system on top of each window – or on top of the browser.
The only way to consolidate these diverse and even conflicting layout models, is to implement several TApplication classes; each one representing the layout model you want to work with. So when your create a project, you pick the layout model you want – and the correct TApplication is chosen and generated for your project.
Actual menus
The RTL have seen a few new widgets added, but the most interesting one is without a doubt the Menu widget. This is a widget that mimics how a normal menu works in a real program.
Creating a menu might not sound interesting, but it’s actually a small challenge under HTML. Not the coding itself, but dealing with menu presentation without visual artifacts. Whenever you click a menu that has a sub-menu attached, the new menu is created from code dynamically. It’s positioned at the end of it’s invoker (to the right of the parent menu item) and should only show up when all it’s child elements have been created.
This was very tricky to get right under a competing system, because the way elements was created was, well, wrong. You want to avoid reflows at all cost during the constructor – otherwise there will be visual artifacts and flickering. But that is not an issue under QTX. And the speed is insane. Even with 100 recursive items on a menu container, it’s virtually instantaneous.

If you are wondering why this makes any difference, you have to remember Quartex Media Desktop. This is not a simple toy with an onClick event, but can be bound into the process tree of the media desktop. The new code is barely 500 lines of code, the older version was over 3000 lines of code.
The goal for the IDE is that you can create a full desktop as a project. Not just programs that should run on the desktop (and its Ragnarok message protocol interface) – but the actual desktop system, which also covers several node.js system services.
The reason this is cool is because this enables you to deliver full scale, desktop level software purely through the browser. Such a desktop would be suitable for a school, a tutoring company, as an intranet – or for teams that need to share files, chat in realtime — and do their software development via the same web interface.
So it’s “a little bit” bigger than some mock desktop.
Come join the fun!
Want to support the project? All financial backers that donates $100+ get their name in the product, access to the full IDE source-code on completion, and access to the Quartex Media Desktop system (which is a complete web desktop with a clustered back-end, compiled to JavaScript and running on node.js. Portable, platform and chipset independent, and very powerful).
A smaller sum monthly is also welcome. The project would not exist without members backing it with $100, $200 etc every month. This both motivates and helps me allocate hours for continuous work.
When the IDE is finished you will also have access to the IDE source-code through special dispensation. Backers have rights since they have helped create the project.

All donations are welcome, both large and small. But donations over $100, especially reoccurring, is what drives this project forward.
Remember to send me a message on Facebook so I can add you to the Admin group: https://www.facebook.com/quartexnor/
Quartex Pascal, convergence is near
A Quartex Cluster of 5 x ODroid XU4. A $400 super computer running Quartex media Desktop. Enough to power a school.
I only have the weekends to work on Quartex Pascal, but I have spent the past 18 months tinkering away, making up for wasted time. So I’m just going to leave some pictures here for you to enjoy.
Note: I was asked on LinkedIn if this has anything to do with Smart Mobile Studio, and the answer is a resounding no. I have nothing to do with Smart any more. QTX Pascal is a completely separate project that is written from scratch by yours truly.
The QTX Framework was initially a library I created back in 2014, but it has later been completely overhauled and turned into a full RTL. It is not compatible with Smart Pascal and has a completely different architecture.
QTX Pascal is indirectly funded by the Amiga Retro Community (which might sound strange, but the technical level of that community is beyond anything I have encountered elsewhere) since QTX is central to the creation of the Quartex Media Desktop. It is a shame that Embarcadero decided to not back the project. The compiler and toolchain would have been a part of Delphi by now, and I wouldn’t have to write a separate IDE. But when they see what this system can deliver in terms of services, database work, mobile and embedded -they might regret it. The project only accepts donation funding, I am not interested in investors or partners. If you want a vision turned into reality, you gotta do it yourself. Everything else just gets in the way.
For developers by developers
Quartex Pascal is made for the community. It will be free for students and open-source projects. And a commercial license will never exceed $300. It is a shareware license and the financial aspects is purely to help fund further research and development of the desktop cloud platform. The final goal (CloudForge) is to compile the IDE itself to JavaScript, so people only need a browser to write enterprise level applications via Quartex Media Desktop. When that is finished, my work is done – and people have a clear path to the future.
Unlike other systems, QTX started with the non-visual stuff, so the system has a well implemented infrastructure for writing universal services and servers, using node.js as a deployment host. Services are also Docker friendly. Runs without change on Windows, Mac OS, Linux and a wealth of embedded systems and SBCs (single board computers)

A completely new RTL written from scratch generates close to native speed JS, highly compatible (even with legacy browsers) and rock solid

There are several display modes for QTX forms, from dynamic to absolute positioning. You can mix and match between HTML and QTX code, including a HTML5 compliant WYSIWYG editor and style manager. Makes content handling a lot easier

Write object pascal, JavaScript, HTML, LDEF (webassembly), node.js services – or mix and match between them all for maximum potential. Writing mobile applications is now ridiculously easy compared to “other tools” out there.
Oh and for the proverbial frosting — The full clustered Quartex Media desktop and services is a project type. Thats right. A complete cloud infrastructure suitable for teams, kiosks, embedded, schools, intranets – and even an replacement OS for ChromeOS. You don’t need to interface with Amazon, you get your own Amazon (optional naturally).

Filesystem over websocket, IPC between hosted apps and desktop, full back-end services that are clustered, and run on anything from a Raspberry PI 4 to low-cost ARM SBCs.

Web Assembly made easy. Both for Delphi and QTX

Let there be rock
Oh, and documentation. Loads and loads of documentation.

Proper documentation, both class overview and explanations that a human being has written is paramount for learning and getting up to speed quickly.
I don’t have vacation this year, which means I only have weekends to tinker away. But i have spent the past 18-ish months preparing and slowly finishing the pieces I needed. From vector containers to form design controls, to a completely re-written RTL from scratch — so yeah. This time I’m doing it my way.
Delphi and the absolute keyword
There is a lot of hidden gems in the Delphi environment and compiler, and while some might regard the “absolute” keyword as obsolete, I could not disagree more; in fact I find it to be one of the most useful, flexible aspects of Delphi (and object pascal in general).
The absolute keyword allows you to define a variable of a specific type, yet instruct the compiler that it should use the memory of another variable. I cannot stress how useful this can be when used right, and how much cleaner it can make code that deal with different classes or types – that are binary compatible.
Tab pages revisited
Unlike most I try to avoid the form designer when I can. Im not purist about it, I just find that inheriting out your own controls and augmenting them results in significantly faster code, as well as a fine grained control that ordinary DFM persistence can’t always deliver.
For example: Lets say you have inherited out your own TPageControl. You have also inherited out a few TTabSheet based classes, populating the tabsheets during the constructor – so there is no design data loaded – resulting in faster display time and a more responsive UI.
In one of my events, which is called as TabSheet class is created, allowing me to prepare it, like set the icon glyph for the tab, its caption and so on – the absolute keyword makes my code faster (since there is no type-casting) and more elegant to read.
All I have to do is check for the type, and once I know which type it is, I use the variable of that type that share memory with the initial type, TTabSheet. Like this:
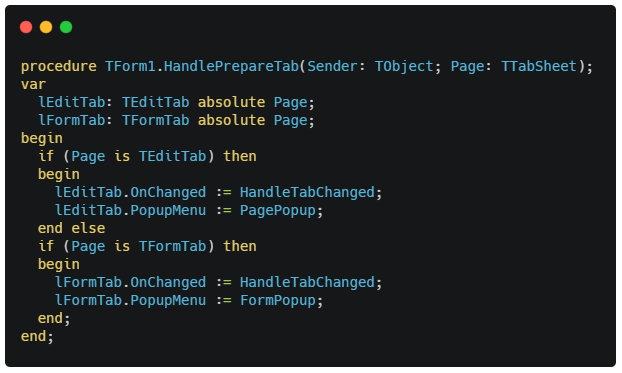
Obviously this is not a live example, its written like this purely to make a point. Namely that the Page parameter can be accessed as a different type without allocating variables or typecasts. Im sure there are some memory use, but i find the above more elegant than 3 x nested if/then/else before you can even touch the pointer.
While this is just a small, miniscule -bordering on pseudo example, the use of absolute can help speed up intensive code by omitting typecasts. Perhaps not above, but in other, more intensive routines dealing with graphics.
It is actually a tremendous help when dealing with low level data conversion (like dealing with 8, 15, 16, 24 and 32 bpp data. When you call routines thousands of times, every bit helps – and absolute is one of those keywords that saves a few cycles per use.
Absolute is definitely one of Delphi’s un-sung heroes. But it’s a scalpel, not a chainsaw!
Using Delphi to fight the Corona Pandemic
I just published an article on Idera’s Community website, focusing on how Delphi and Object Pascal plays a key role in fighting the Corona Pandemic.
My focus this time is on DIPS AS, a Norwegian corporation that produces a wide range of software solutions for hospitals, medical facilities and special care units. They were amoung the first companies in Norway to provide a Covid-19 module through their FastTrak application, which is completely written in Delphi.
Click the link to read the article (or just click the preview image below): https://community.idera.com/developer-tools/b/blog/posts/delphi-in-healthcare-fighting-the-corona-pandemic
Vector Containers For Delphi and FPC
Edit: Version 1.0.1 has been released, with a ton of powerful features. Read about it here and grab your fork: https://jonlennartaasenden.wordpress.com/2020/04/13/qtx-framework-for-delphi-and-fpc-is-available-on-bitbucket/
If you have been looking at C++ and envied them their std::vector classes, wanting the same for Delphi or being able to access untyped memory using a typed-view (basically turning a buffer into an array of <T>) then I have some good news for you!
Vector containers, unified storage model and typed views are just some of the highlights of my vector-library. I did an article on the subject at the Embarcadero community website, so head over and read up on how you can enjoy these features in your Delphi application!
I also added FreePascal support, so that the library can be used with TMS Web Framework.
Head over to the Embarcadero Community website to read the full article
Delphi Dying? Think again, Tiobe
At the beginning of last week, Tiobe once again threw a punch at Object Pascal. Playing the whole “Delphi is dying” tune, while focusing on outdated and quite frankly irrelevant episodes from the past. Hoping no doubt, to leave the reader with an impression that Delphi is stuck in the 90s.
This is the same pattern we often see whenever Delphi or Object Pascal in general experience significant growth; or to be blunt, when the author cannot be bothered to think independently, but simply parrot hearsay and misinformation on autopilot.
It is lame, superficial and Tiobe’s biggest mistake to date.

Guess “alternative news” is no longer limited to individuals like Alex Jones
Just to underline the problem areas here. The ranking is based on their internal system (there is no standard for how to rank popularity), and while I have issues with how they build up their score, it’s ultimately the March editorial text that has caused irritation and shock. You don’t declare a language as dead when there are over 10 million developers using it. This type of editorial could have very real consequences – which in turn brings us to their ranking system and how they arrived at their conclusions.
I would have understood their statement if it was issued between 2007 and 2010, because Delphi was at that time transitioning between Borland and Embarcadero. But to issue something like this in 2020? After a decade worth of restoration, optimization, modernization and above all – forging a thriving community that goes from victory to victory month after month, year after year? It makes absolutely no sense.
Significant growth
In 2018 there were roughly six million Delphi developers (I worked at Embarcadero at the time), with a total estimate of ten million Object Pascal developers worldwide when counting all alternative compilers, dialects and indeed – known piracy issues.
“Tiobe failed stupendously in their data mining operation, they seem to be oblivious regarding the demographic in which the language is used”
Since that time Delphi has made strides into the universities in Scandinavia, South-America and the Middle-East. Turkey recently announced their dedication to native and archetypal software development with Delphi (provided free for students), which adds a whopping one million students to the already large body of users.
Embarcadero has slowly but steadily rebuilt much of the infrastructure that existed under Borland. From professional training at Embarcadero Academy, to entry level training at LearnDelphi.org. The Idera community pages likewise produce a large body of articles on a weekly basis. Comparing the Delphi and C++Builder ecosystem today with it’s tragic state back in 2010, is like day and night.
Training is available for both Enterprise level developers and students alike
With so much positive happening in the world of Object Pascal, Tiobe’s article comes across as a grave, intentional misrepresentation at worst, or an intellectual emergency at best. It is completely out of place and carries the tell-tell signs of an echo chamber.
Tiobe has lost all credibility
I have to be honest. I have never taken Tiobe that serious, because they have made to many mistakes in the past to have any form of credibility when it comes to Delphi and Object Pascal as a language. And when I say mistakes, I mean monumental blunders that just annihilate all possibility that they treat languages on equal footing.
“not only have Tiobe failed in their indexing, they have completely and utterly misunderstood the demographic in which the language is used”
If we go back a decade, Tiobe actually based their numbers on the keyword “Pascal”. In other words they excluded not just Delphi commits to GitHub, BitBucket and similar services – they also managed to exclude Freepascal and every subsequent dialect that signify Object Pascal as a whole. So for quite some time their entire statistics was based on the off chance that people typed “Pascal” in their project or commit entries.
To make matters worse, their search tech was not smart enough to recognize “Pascal” in composite words. So if you wrote “ObjectPascal” in a single word, the commit was excluded; As was “Freepascal”, “Smartpascal”, “Oxygenepascal” and variations using a hyphen (and the same for abbreviations).
Developers also use the term Lazarus and FPC interchangeably since Lazarus typically means people use the LCL, the visual framework used to write desktop applications with Freepascal. So while Freepascal has nothing to do with Delphi in terms of intellectual property, the two compilers are used by the community as a whole.
But let’s look at why Tiobe’s indexing fails for Delphi. Just what are they doing wrong?
- Delphi has been around for 25 years, and it’s roots stretch back to the birth of C. Using Stack Overflow as an indicator for popularity is ludacris, since the majority of errors and problems have been largely ironed out in the past, leaving only extremely advanced and rare topics. If problems is the criteria, then I guess that explains why C# and Java soars in the ranking.
- Nobody searches google for “Delphi programming”. You search for explicit topics like composite polygon clipping with GDI+ and then add “delphi” to limit the search to said language. Just like C/C++, Object Pascal is an archetypal language. It stretches from kernel work with inline assembly, to cloud services and HTML5 rendering. So the topics people search for are usually straight out of the operating-system strata.
- Delphi developers communicate in dedicated groups, such as Delphi Developer on Facebook. There is also a thriving community on the Delphi Praxis forums, not to mention the Freepascal forums. None of which seem to be included in Tiobe’s activity statistics.
- Object Pascal has several frameworks and run-time libraries. Delphi ships with two:
- Classical VCL for Windows development (which has seen enormous optimization in the past 8 years, covering UWP, WinRT et-al).
- And then there is FireMonkey (FMX) for multi-platform, embedded and mobile targets.
- Freepascal operates with its own, open-source variation called the LCL
- Freepascal also targets WebAssembly and JavaScript and have variations of the LCL adapted those targets
- And then there is third party, commercial alternatives that covers HTML5/JS like TMS WebCore, Smart Pascal, Oxygene Pascal and the upcoming Quartex Pascal. Around these runtime libraries (VCL, FMX and LCL) there are thousands of libraries, components and frameworks, large and small, that don’t necessarily put “Delphi” or “Object Pascal” in their metadata.
- Tiobe also fails to include feeds like BeginEnd.net or DelphiFeeds, which syndicate on average 3000 unique blog-posts a year, representing a consistent and very much alive stream of information and content.
Delphi and Freepascal, which represents the most widely used compilers, are predominantly used to write commercial, closed source products. Which by consequence means that code and the activity involved is not public. For Tiobe to so utterly misunderstand the demographic for Object Pascal in general, is quite frankly outrageous. If you are going to rank a language that involves millions of users -then at least have the decency of investigating the communities it involves.
Excluding the factors I have outlined above, makes as much sense as excluding mono from C#.
Incompetence or plain ignorance?
It was only after an avalanche of complaints in 2014, orchestrated by yours truly, where members of the Delphi Developer group on Facebook sent complaints en-mass to Tiobe that they addressed the use of “Pascal” to represent Delphi and associated dialects. Yet for all the complaints, outlined in letters that no sentient human being could misunderstand – all Tiobe managed to do was to add “Object Pascal” to their list. Which, believe it or not, was unfamiliar to them.

It’s funny because it’s true
But do you think they bothered to do it right? Afraid not. Instead of aggregating all of the dialects, frameworks and variations of names under a single banner, they still to this day operate with two very specific search elements, namely “Delphi” or “Object Pascal”.
I sure hope the dairy industry doesn’t hire Tiobe to do statistics on milk, because if their coverage of Object Pascal is anything to go by, they will be ranking by yogurt.
No updates since 2018? Really Tiobe?
When a global Index service like Tiobe manage to write, and I quote:
“However, the latest Delphi release is from 2018” -Source: Tiobe, March report
You really have to ponder if human beings are involved in their business at all. I’m not expecting much, honestly, but I do expect them to interact with the community they supposedly track and build a statistic on. Have they visited Delphi Developer and talked to the admins about growth numbers? Have they talked to Embarcadero to get some figures and coverage there? Did they contact the Freepascal community to get some download statistics from them?
Delphi 10.3 was released on november 21st 2019. The version that Tiobe seem to think is the last update, is in fact the last release with a city name (which was launched in 2018). Since then there have been three successive, regular updates; most developers are now using version 10.3.3. With 10.3.4 about to be released. This just underlines how oblivious Tiobe is to our part of the industry.
Modern Delphi is used by millions of professional developers globally
Delphi and Freepascal is different in more ways than one, but beyond language compatibility there is one aspect that is quintessential for them both; namely their role in the commercial sector. Where other languages, like C/C++ or (for example) JavaScript see a lot of open-source activity, especially with regards to Linux and Node.js – Delphi and Freepascal are predominantly used to write high-quality, commercial, closed source business applications. In other words, the vast majority of code produced by the millions of Object Pascal developers around the world – is never publicly committed to GitHub or BitBucket.
So not only have Tiobe failed stupendously in their data mining operation, they seem oblivious to the demographic in which the language is used.

The selection of books, video tutorials and coding material for Delphi is recovering at a rapid pace. And much like C/C++ there are classic books on Amazon that are just as relevant today as they were 10 years ago. Thankfully Delphi don’t suffer the “learn Delphi in 2 weeks” style books, because any developer worth his salt knows that such books are for the gullible and naive.
Developers use Delphi and Freepascal to deliver rock solid, data driven services; services that is expected to run 24/7 with zero downtime, processing millions of transactions. Delphi is used to write medical software that manages networks of hospitals, with tens of thousands of patients. Delphi is used by banks to power their ATM machines, and Delphi is used to do the heavy lifting in thousands of POS (point of sale) terminals across Europe. Terminals that don’t have time to wait for a garbage collector to kick in, only to cause catastrophic CPU spikes (I won’t mention names, but attempting to switch to C# was a disaster for one of the biggest POS terminal suppliers in Europe).

Delphi represents the back-bone of the medical software industry in Scandinavia and Europe at large. Many have tried to replace Delphi, but end up with expensive lessons in why archetypal languages are indeed called archetypal.
Object Pascal is used by governments, fortune 500 companies and the guy with a million dollar idea working out of his parents garage; It is used to write cloud accounting software, invoicing systems and medical journaling; It is used by the music industry and graphical design. There are large and extremely successful products out there that don’t advertise that it’s written in Delphi (just like you don’t stamp “made with C++” on a piece of software). You would be surprised!
Object Pascal it’s used by developers who value speed, security, creative freedom and the benefit of a mature feature matrix that only C/C++ and Object Pascal brings. C is by definition three years older than Pascal, but these two archetypal languages have evolved side by side.
There is a reason these two languages represented the university curriculum for close to two decades; further still if we include Turbo Pascal. And Delphi is once again returning home to academia. To the applause of teachers who were forced to teach Java, and hated every minute of it (I helped setup two universities with Delphi in Norway, so I have some first hand accounts in the matter).
Reflections
Since Delphi is growing aggressively these days, Embarcadero is making waves. A few months back we saw how a well known team of C# influencers took a stab at Delphi (and me in particular, no doubt because I have been so outspoken). And as Delphi now returns to academia – Tiobe is demonstrating a bias that leaves little to the imagination. Especially when you know their numbers account for nothing and are bordering on fiction.

If I didn’t know better, I would say someone is worried. And it’s not the Delphi and Freepascal communities. Modern Delphi is a power-house for software development, and it has the potential to disrupt and restore the devtool market.
There is a lot of money involved, so I am not surprised we are seeing a string of attempts at undermining the importance of Object Pascal. I had hoped Tiobe would adopt a higher standard though.
Then again, the ship of credibility sailed when they couldn’t tell Turbo Pascal from Object Pascal.
Delphi 25th Webinar signup
 Delphi is turning 25 and in connection with that, Jim Mckeeth is preparing a webinar! So make sure you register for the webinar in time! There is some very special and unique stuff lined up, so this is going to rock!
Delphi is turning 25 and in connection with that, Jim Mckeeth is preparing a webinar! So make sure you register for the webinar in time! There is some very special and unique stuff lined up, so this is going to rock!
You can register here:
https://register.gotowebinar.com/register/8514999980241029644
25 years, wow. It seems only yesterday that I moved from Turbo Pascal to Delphi, and here we are a quarter of a century later. Such a wonderful language platform.
Very much looking forward to this talk — see you there guys!
Five unique features in Delphi for Windows 10
I recently did an article on the Idera / Embarcadero Community website on Interbase 2020 and why that should be your next database.
Im following up with a second article about five features of Delphi that are intimately connected to Windows 10. I know that a lot of people are still clinging to Windows 7, but Microsoft phased that out last week, which means it’s now officially a legacy OS. So if you haven’t bothered updating, have a peek and think it over.
Turkish ministry of education secures free access to Delphi for an estimated one million students
Edit: The title in my initial post could be misinterpreted, so i have altered it to better reflect the nature of the situation. My apologies for the misunderstanding, I used the initial text copied verbatim from the source, translated from Turkish to Norwegian (and further to English), and in this case an important nuance was lost in that process.
The ministry of education in Turkey recently announced that they will be offering Delphi free of charge to their body of students. An estimated one million students will thus have access to Delphi through this initiative.

Getting object-pascal back into universities and education is very important. Not just for Delphi as a product or Embarcadero as a company, but to ensure that the next generation of software developers are given a firm grasp on fundamental programming concepts; concepts that represent the building-blocks that all software rests on, and that will benefit the students for a lifetime.
I find it incredibly sad that Java and C# somehow crept into the curriculum of computer sciences around the turn of the century. The result of that opportunistic move is that we have several generations of developers who has graduated utterly oblivious to fundamental concepts; concepts such as memory management, interrupts, low-level optimization, inline assembler and (to be blunt) how a computer actually works beyond the desktop. This is why a formal education of C and Pascal is powerful and enduring. It gives the student a depth and wingspan that is hard to match.
Object Pascal as a language (including Freepascal, Oxygene and various alternative compilers) have been fluctuating between #11 and #14 on the Tiobe Index for a few years. Tiobe is an index that tracks the use and popularity of languages around the world, and helps companies get an indication of where to invest. So despite what people have been led to believe, Delphi has seen stable growth for many years and is far more widespread than sceptics like to admit.
As an ardent Delphi developer myself this is excellent news! Not only will it help the next generation of students learn proper engineering from the ground up – but it will also help to retire some of the unfounded myths surrounding the language (and Delphi in particular) that is sadly still in circulation. Most of these rumors stem from the hostile takeover (or elimination) of Borland by Microsoft some two decades ago, and does in no way reflect the reality of 2020. Delphi in particular has been through several phases of evolution, and is today en par with it’s companion language C/C++.
I am thrilled that so many young developers will now have access to a modern and relevant Delphi edition. Delphi has been a favorite of teachers and students everywhere, and the return of Delphi to academia – is a sign that the age of compromise is losing its grip.
Thank you to Hür Akdülger for informing the Delphi Developer community about this. Truly a monumental sign of growth. Congratulations Embarcadero and the Turkish students!
Source [in Turkish]:
https://www.timeturk.com/meb-den-1-milyon-meslek-lisesi-ogrencisine-yazilim-egitimi/haber-1337091
Interbase for 2020 and beyond
I just published an article about InterBase on the Embarcadero community pages! Interbase is a much loved database that has seen some radical improvements. Check out my top 5 reasons to use InterBase with your Delphi, C++Builder or Sencha applications here: https://community.idera.com/developer-tools/b/blog/posts/five-reasons-to-use-interbase-in-2020-and-beyond
Check out my top five InterBase features for 2020 and beyond
Nodebuilder, QTX and the release of my brand new social platform
First, let me wish everyone a wonderful new year! With xmas and the silly season firmly behind us, and my batteries recharged – I feel my coding fingers itch to get started again.
2019 was a very busy year for me. Exhausting even. I have juggled both a full time job, kids and family, as well as our community project, Quartex Media Desktop. And since that project has grown considerably, I had to stop and work on the tooling. Which is what NodeBuilder is all about.
I have also released my own social media platform (see further down). This was initially scheduled for Q4 2020, but Facebook pissed me off something insanely, so I set it up in december instead.
NodeBuilder

For those of you that read my blog you probably remember the message system I made for the Quartex Desktop, called Ragnarok? This is a system for dealing with message dispatching and RPC, except that the handling is decoupled from the transport medium. In other words, it doesnt care how you deliver a message (WebSocket, UDP, REST), but rather takes care of serialization, binary data and security.
All the back-end services that make up the desktop system, are constructed around Ragnarok. So each service exposes a set of methods that the core can call, much like a normal RPC / SOAP service would. Each method is represented by a request and response object, which Ragnarok serialize to a JSON message envelope.
In our current model I use WebSocket, which is a full duplex, long-term connection (to avoid overhead of having to connect and perform a handshake for each call). But there is nothing in the way of implementing a REST transport layer (UDP is already supported, it’s used by the Zero-Config system. The services automatically find each other and register, as long as they are connected to the same router or switch). For the public service I think REST makes more sense, since it will better utilize the software clustering that node.js offers.

Node Builder is a relatively simple service designer, but highly effective for our needs
Now for small services that expose just a handful of methods (like our chat service), writing the message classes manually is not really a problem. But the moment you start having 20 or 30 methods – and need to implement up to 60 message classes manually – this approach quickly becomes unmanageable and prone to errors. So I simply had to stop before xmas and work on our service designer. That way we can generate the boilerplate code in seconds rather than days and weeks.
While I dont have time to evolve this software beyond that of a simple service designer (well, I kinda did already), I have no problem seeing this system as a beginning of a wonderful, universal service authoring system. One that includes coding, libraries and the full scope of the QTX runtime-library.
In fact, most of the needed parts are in the codebase already, but not everything has been activated. I don’t have time to build both a native development system AND the development system for the desktop.

NodeBuilder already have a fully functional form designer and code editor, but it is dormant for now due to time restrictions. Quartex Media Desktop comes first
But right now, we have bigger fish to fry.
Quartex Media Desktop
We have made tremendous progress on our universal desktop environment, to the point where the baseline services are very close to completion. A month should be enough to finish this unless something unforeseen comes up.

Quartex Media Desktop provides an ecosystem for advanced web applications
You have to factor in that, this project has only had weekends and the odd after work hours allocated for it. So even though we have been developing this for 12 months, the actual amount of days is roughly half of that.
So all things considered I think we have done a massive amount of code in such a short time. Even simple 2d games usually take 2 years of daily development, and that includes a team of at least 5 people! Im a single developer working in my spare time.
So what exactly is left?
The last thing we did before xmas was upon us, was to throw out the last remnants of Smart Mobile Studio code. The back-end services are now completely implemented in our own QTX runtime-library, which has been written from scratch. There is not a line of code from Smart Mobile Studio in QTX, which means we no longer have to care what that system does or where it goes.
To sum up:
- Push all file handling code out of the core
- Implement file-handling as it’s own service
Those two steps might seem simple enough, but you have to remember that the older code was based on the Linux path system, and was read-only.
So when pushing that code out of the core, we also have to add all the functionality that was never implemented in our prototype.

Each class actually represents a separate “mini” program, and there are still many more methods to go before we can put this service into production.
Since Javascript does not support threads, each method needs to be implemented as a separate program. So when a method is called, the file/task manager literally spawns a new process just for that task. And the result is swiftly returned back to the caller in async manner.
So what is ultimately simple, becomes more elaborate if you want to do it right. This is the price we pay for universality and a cluster enabled service-stack.
This is also why I have put the service development on pause until we have finished the NodeBuilder tooling. And I did this because I know by experience that the moment the baseline is ready, both myself and users of the system is going to go “oh we need this, and that and those”. Being able to quickly design and auto-generate all the boilerplate code will save us months of work. So I would rather spend a couple of weeks on NodeBuilder than wasting months having to manually write all that boilerplate code down the line.
What about the QTX runtime-library?
Writing an RTL from scratch was not something I could have anticipated before we started this project. But thankfully the worst part of this job is already finished.
The RTL is divided into two parts:
Non Visual code. Classes and methods that makes QTX an RTL- Visual code. Custom Controls + standard controls (buttons, lists etc)
Visual designer
As you can see, the non-visual aspect of the system is finished and working beautifully. It’s a lot faster than the code I wrote for Smart Mobile Studio (roughly twice as fast on average). I also implemented a full visual designer, both as a Delphi visual component and QTX visual component.
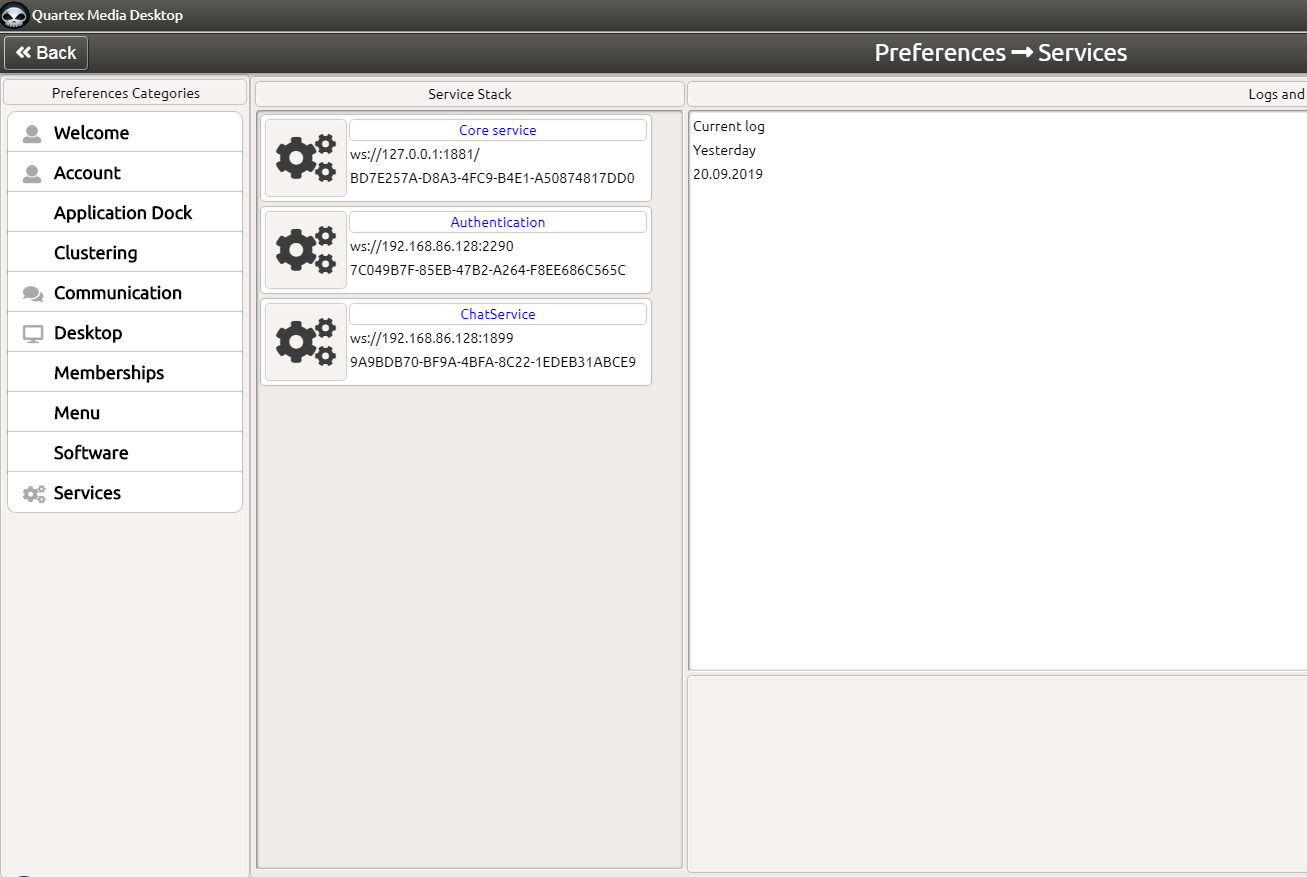
Quartex Media Desktop makes running on several machines [cluster] easy and seamless
Why is the QTX Runtime-Library important again?
When the desktop is out the door, the true work begins! The desktop has several roles to play, but the most important aspect of the desktop – is to provide an ecosystem capable of hosting web based applications. Offering features and methods traditionally only found in Windows, Linux or OS X. It truly is a complete cloud system that can scale from a single affordable SBC (single board computer), to a high-end cluster of powerful servers.
Clustering and writing distributed applications has always been difficult, but Quartex Media Desktop makes it simple. It is no more difficult for a user to work on a clustered system, as it is to work on a normal, single OS. The difficult part has already been taken care of, and as long as people follow the rules, there will be no issues beyond ordinary maintenance.
And the first commercial application to come out of Quartex Components, is Cloud Forge, which is the development system for the platform. It has the same role as Visual Studio for Windows, or X Code for Apple OS X.

The Quartex Media Desktop Cluster cube. A $400 super computer
I have prepared 3 compilers for the system already. First there is C/C++ courtesy of Clang. So C developers will be able to jump in and get productive immediately. The second compiler is freepascal, or more precise pas2js, which allows you to compile ordinary freepascal code (which is highly Delphi compatible) to both JavaScript and WebAssembly.
And last but not least, there is my fork of DWScript, which is the same compiler that Smart Mobile Studio uses. Except that my fork is based on the absolute latest version, and i have modified it heavily to better match special features in QTX. So right out of the door CloudForge will have C/C++, two Object Pascal compilers, and vanilla Javascript and typescript. TypeScript also has its own WebAssembly compiler, so doing hard-core development directly in a browser or HTML5 viewport is where we are headed.
Once the IDE is finished I can finally, finally continue on the LDEF bytecode runtime, which will be used in my BlitzBasic port and ultimately replace both clang, freepascal and DWScript. As a bonus it will emit native code for a variety of systems, including x86, ARM, 68k [including 68080] and PPC.
This might sound incredibly ambitious, if not impossible. But what I’m ultimately doing here -is moving existing code that I already have into a new paradigm.
The beauty of object pascal is the sheer size and volume of available components and code. Some refactoring must be done due to the async nature of JS, but when needed we fall back on WebAssembly via Freepascal (WASM executes linear, just like ordinary native code does).
A brand new social platform
During december Facebook royally pissed me off. I cannot underline enough how much i loath A.I censorship, and the mistakes that A.I does – in which you are utterly powerless to complain or be heard by a human being. In my case i posted a gif from their own mobile application, of a female body builder that did push-ups while doing hand-stands. In other words, a completely harmless gif with strength as the punchline. The A.I was not able to distinguish between a leotard and bare-skin, and just like that i was muted for over a week. No human being would make such a ruling. As an admin of a fairly large set of groups, there are many cases where bans are the result. Disgruntled members that acts out of revenge and report technical posts about coding as porn or offensive. Again, you are helpless because there are nobody you can talk to about resolving the issue. And this time I had enough.
It was always planned that we would launch our own social media platform, an alternative to Facebook aimed at adult geeks rather than kids (Facebook operates with an age limit of 12 years). So instead of waiting I rushed out and set up a brand new social network. One where those banale restrictions Facebook has conditioned us with, does not apply.
Just to underline, this is not some simple and small web forum. This is more or less a carbon copy of Facebook the way it used to be 8-9 years ago. So instead of having a single group on facebook, we can now have as many groups as we like, on a platform that looks more or less identical to Facebook – but under our control and human rules.
Amigadisrupt.com is a brand new social media platform for geeks
You can visit the site right now at https://www.amigadisrupt.com. Obviously the major content on the platform right now is dominated by retro computing – but groups like Delphi Developer and FPC developer has already been setup and are in use. But if you are expecting thousands of active users, that will take time. We are now closing in on 250 active users which is pretty good for such a short period of time. I dont want a platform anywhere near as big as FB. The goal is to get 10k users and have a stable community of coders, retro geeks, builders and creative individuals.
AD (Amiga Disrupt) will be a standard application that comes with Quartex Media Desktop. This is the beauty of web technology, in that it can unify different resources under one roof. And we will have our cake and eat it come hell or high water.
Disclaimer: Amiga Disrupt has a lower age limit of 18 years. This is a platform meant for adults. Which means there will be profanity, jokes that would get you banned on Facebook and content that is not meant for kids. This is hacker-land, and political correctness is considered toilet paper. So if you need social toffery like FB and Twitter deals with, you will be kicked by one of the admins.
After you sign up your feed will be completely empty. Here is how to get it started. And feel free to add me to your friends-list!
Hydra, what’s the big deal anyway?
RemObjects Hydra is a product I have used for years in concert with Delphi, and like most developers that come into contact with RemObjects products – once the full scope of the components hit you, you never want to go back to not using Hydra in your applications.
Note: It’s easy to dismiss Hydra as a “Delphi product”, but Hydra for .Net and Java does the exact same thing, namely let you mix and match modules from different languages in your programs. So if you are a C# developer looking for ways to incorporate Java, Delphi, Elements or Freepascal components in your application, then keep reading.
But let’s start with what Hydra can do for Delphi developers.
What is Hydra anyways?
Hydra is a component package for Delphi, Freepascal, .Net and Java that takes plugins to a whole new level. Now bear with me for a second, because these plugins is in a completely different league from anything you have used in the past.
In short, Hydra allows you to wrap code and components from other languages, and use them from Delphi or Lazarus. There are thousands of really amazing components for the .Net and Java platforms, and Hydra allows you compile those into modules (or “plugins” if you prefer that); modules that can then be used in your applications like they were native components.
Hydra, here using a C# component in a Delphi application
But it doesn’t stop there; you can also mix VCL and FMX modules in the same application. This is extremely powerful since it offers a clear path to modernizing your codebase gradually rather than doing a time consuming and costly re-write.
So if you want to move your aging VCL codebase to Firemonkey, but the cost of having to re-write all your forms and business logic for FMX would break your budget -that’s where Hydra gives you a second option: namely that you can continue to use your VCL code from FMX and refactor the application in your own tempo and with minimal financial impact.
The best of all worlds
Not long ago RemObjects added support for Lazarus (Freepascal) to the mix, which once again opens a whole new ecosystem that Delphi, C# and Java developers can benefit from. Delphi has a lot of really cool components, but Lazarus have components that are not always available for Delphi. There are some really good developers in the Freepascal community, and you will find hundreds of components and classes (if not thousands) that are open-source; For example, Lazarus has a branch of Synedit that is much more evolved and polished than the fork available for Delphi. And with Hydra you can compile that into a module / plugin and use it in your Delphi applications.

This is also true for Java and C# developers. Some of the components available for native languages might not have similar functionality in the .Net world, and by using Hydra you can tap into the wealth that native languages have to offer.
As a Delphi or Freepascal developer, perhaps you have seen some of the fancy grids C# and Java coders enjoy? Developer Express have some of the coolest components available for any platform, but their focus is more on .Net these days than Delphi. They do maintain the control packages they have, but compared to the amount of development done for C# their Delphi offerings are abysmal. So with Hydra you can tap into the .Net side of things and use the latest components and libraries in your Delphi applications.
Financial savings
One of coolest features of Hydra, is that you can use it across Delphi versions. This has helped me leverage the price-tag of updating to the latest Delphi.
It’s easy to forget that whenever you update Delphi, you also need to update the components you have bought. This was one of the reasons I was reluctant to upgrade my Delphi license until Embarcadero released Delphi 10.2. Because I had thousands of dollars invested in components – and updating all my licenses would cost a small fortune.
So to get around this, I put the components into a Hydra module and compiled that using my older Delphi. And then i simply used those modules from my new Delphi installation. This way I was able to cut cost by thousands of dollars and enjoy the latest Delphi.
Using Firemonkey controls under VCL is easy with Hydra
A couple of years back I also took the time to wrap a ton of older components that work fine but are no longer maintained or sold. I used an older version of Delphi to get these components into a Hydra module – and I can now use those with Delphi 10.3 (!). In my case there was a component-set for working closely with Active Directory that I have used in a customer’s project (and much faster than having to go the route via SQL). The company that made these don’t exist any more, and I have no source-code for the components.
The only way I could have used these without Hydra, would be to compile them into a .dll file and painstakingly export every single method (or use COM+ to cross the 32-bit / 64-bit barrier), which would have taken me a week since we are talking a large body of quality code. With Hydra i was able to wrap the whole thing in less than an hour.
I’m not advocating that people stop updating their components. But I am very thankful for the opportunity to delay having to update my entire component stack just to enjoy a modern version of Delphi.
Hydra gives me that opportunity, which means I can upgrade when my wallet allows it.
Building better applications
There is also another side to Hydra, namely that it allows you to design applications in a modular way. If you have the luxury of starting a brand new project and use Hydra from day one, you can isolate each part of your application as a module. Avoiding the trap of monolithic applications.
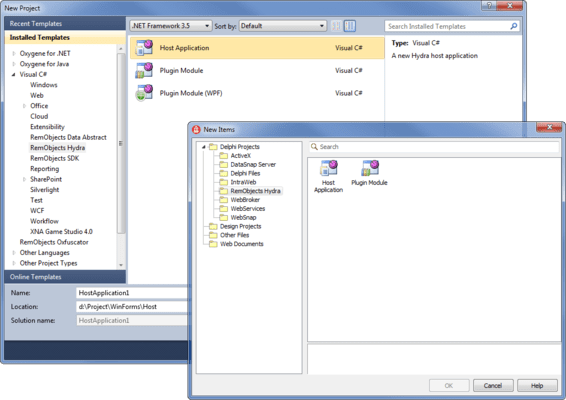
Hydra for .Net allows you to use Delphi, Java and FPC modules under C#
This way of working has great impact on how you maintain your software, and consequently how you issue hotfixes and updates. If you have isolated each key part of your application as separate modules, you don’t need to ship a full build every time.
This also safeguards you from having all your eggs in one basket. If you have isolated each form (for example) as separate modules, there is nothing stopping you from rewriting some of these forms in another language – or cross the VCL and FMX barrier. You have to admit that being able to use the latest components from Developer Express is pretty cool. There is not a shadow of a doubt that Developer-Express makes the best damn components around for any platform. There are many grids for Delphi, but they cant hold a candle to the latest and greatest from Developer Express.
Why can’t I just use packages?
If you are thinking “hey, this sounds exactly like packages, why should I buy Hydra when packages does the exact same thing?“. Actually that’s not how packages work for Delphi.
Delphi packages are cool, but they are also severely limited. One of the reasons you have to update your components whenever you buy a newer version of Delphi, is because packages are not backwards compatible.

Delphi packages are great, but severely limited
A Delphi package must be compiled with the same RTL as the host (your program), and version information and RTTI must match. This is because packages use the same RTL and more importantly, the same memory manager.
Hydra modules are not packages. They are clean and lean library files (*.dll files) that includes whatever RTL you compiled them with. In other words, you can safely load a Hydra module compiled with Delphi 7, into a Delphi 10.3 application without having to re-compile.
Once you start to work with Hydra, you gradually build up modules of functionality that you can recycle in the future. In many ways Hydra is a whole new take on components and RAD. This is how Delphi packages and libraries should have been.
Without saying anything bad about Delphi, because Delphi is a system that I love very much; but having to update your entire component stack just to use the latest Delphi, is sadly one of the factors that have led developers to abandon the platform. If you have USD 10.000 in dependencies, having to pay that as well as buying Delphi can be difficult to justify; especially when comparing with other languages and ecosystems.
For me, Hydra has been a tremendous boon for Delphi. It has allowed me to keep current with Delphi and all it’s many new features, without losing the money I have already invested in components packages.
If you are looking for something to bring your product to the next level, then I urge you to spend a few hours with Hydra. The documentation is exceptional, the features and benefits are outstanding — and you will wonder how you ever managed to work without them.
External resources
Disclaimer: I am not a salesman by any stretch of the imagination. I realize that promoting a product made by the company you work for might come across as a sales pitch; but that’s just it: I started to work for RemObjects for a reason. And that reason is that I have used their products since they came on the market. I have worked with these components long before I started working at RemObjects.
.NetRocks, you made my day!
 A popular website for .Net developers is called dot-net-rocks. This is an interesting site that has been going for a while now; well worth the visit if you do work with the .Net framework via RemObjects Elements, VS or Mono.
A popular website for .Net developers is called dot-net-rocks. This is an interesting site that has been going for a while now; well worth the visit if you do work with the .Net framework via RemObjects Elements, VS or Mono.
Now it turns out that the guys over at dot–net-rocks just did an episode on their podcast where they open by labeling me as a “raving lunatic” (I clearly have my moments); which I find absolutely hilarious, but not for the same reasons as them.
Long story short: They are doing a podcast on how to migrate legacy Delphi applications to C#, and in that context they somehow tracked down an article I posted way back in 2016, which was meant as a satire piece. Now don’t get me wrong, there are serious points in the article, like how the .Net framework was modeled on the Delphi VCL, and how the concepts around CLR and JIT were researched at Borland; but the tone of the whole thing, the “larger than life” claims etc. was meant to demonstrate just how some .Net developers behave when faced with alternative eco-systems. Having managed some 16+ usergroups for Delphi, C#, JavaScript (a total of six languages) on Facebook for close to 15 years, as well as working for Embarcadero that makes Delphi -I speak from experience.
It might be news to these guys that large companies around Europe is still using Delphi, modern Delphi, and that Object Pascal as a language scores well on the Tiobi index of popular programming languages. And no amount of echo-chamber mentality is going to change that fact. Heck, as late as 2018 and The Walt Disney Company wanted to replace C# with Delphi, because it turns out that bytecodes and embedded tech is not the best combination (cpu spikes when the GC kicks in, no real-time interrupt handling possible, GPIO delays, the list goes on).
I mean, the post i made back in 2016 is such obvious, low-hanging fruit for a show their size to pound on. You have this massive show that takes on a single, albeit ranting (and probably a bit of a lunatic if I don’t get my coffee) coder’s post. Underlying in the process how little they know about the object pascal community at large. They just demonstrated my point in bold, italic and underline 😀
Look before you shoot
DotNetRocks is either oblivious that Delphi still have millions of users around the world, or that Pascal is in fact available for .Net (which is a bit worrying since .Net is supposed to be their game). The alternative is that the facts I listed hit a little too close to home. I’ll leave it up to the reader to decide. Microsoft has lost at least 10 Universities around Europe to Delphi in 2018 that I know of, two of them Norwegian where I was personally involved in the license sales. While only speculation, I do find the timing for their podcast and focus on me in particular to be, “curious”.
 And for the record, the most obvious solution when faced with “that legacy Delphi project”, is to just go and buy a modern version of Delphi. DotNetRocks delivered a perfect example of that very arrogance my 2016 post was designed to convey; namely that “brogrammers” often act like Delphi 7 was the last Delphi. They also resorted to lies to sell their points: I never said that Anders was dogged for creating Delphi. Quite the opposite. I simply underlined that by ridiculing Delphi in one hand, and praising it’s author with the other – you are indirectly (and paradoxically) invalidating half his career. Anders is an awesome developer, but why exclude how he evolved his skills? Ofcourse Ander’s products will have his architectural signature on them.
And for the record, the most obvious solution when faced with “that legacy Delphi project”, is to just go and buy a modern version of Delphi. DotNetRocks delivered a perfect example of that very arrogance my 2016 post was designed to convey; namely that “brogrammers” often act like Delphi 7 was the last Delphi. They also resorted to lies to sell their points: I never said that Anders was dogged for creating Delphi. Quite the opposite. I simply underlined that by ridiculing Delphi in one hand, and praising it’s author with the other – you are indirectly (and paradoxically) invalidating half his career. Anders is an awesome developer, but why exclude how he evolved his skills? Ofcourse Ander’s products will have his architectural signature on them.
Not once did they mention Embarcadero or the fact that Delphi has been aggressively developed since Borland kicked the bucket. Probably hoping that undermining the messenger will somehow invalidate the message.
Porting Delphi to C# manually? Ok.. why not install Elements and just compile it into an assembly? You don’t even have to leave Visual Studio
Also, such an odd podcast for professional developers to run with. I mean, who the hell converts a Delphi project to C# manually? It’s like listening to a graphics artist that dont know that Photoshop and Illustrator are the de-facto tools to use. How is that even possible? A website dedicated to .Net, yet with no insight into the languages that run on the CLR? Wow.
If you want to port something from Delphi to .Net, you don’t sit down and manually convert stuff. You use proper tools like Elements from RemObjects; This gives you Object-Pascal for .Net (so a lot of code will compile just fine with only minor changes). Elements also ships with source-conversion tools, so once you have it running under Oxygene Pascal (the dialect is called Oxygene) you either just use the assemblies — or convert the Pascal code to C# through a tool called an Oxidizer.
The most obvious solution is to just upgrade to a Delphi version from this century
The other solution is to use Hydra, also a RemObjects product. They can then compile the Delphi code into a library (including visual parts like forms and frames), and simply use that as any other assembly from within C#. This allows you to gradually phase out older parts without breaking the product. You can also use C# assemblies from Delphi with Hydra.
So by all means, call me what you like. You have only proved my point so far. You clearly have zero insight into the predominant Object-Pascal eco-systems, you clearly don’t know the tools developers use to interop between arcetypical and contextual languages — and instead of fact checking some of the points I made, dry humor notwithstanding, you just reacted like brogrammers do.
Well, It’s been weeks since I laughed this hard 😀 You really need to check before you pick someone to verbally abuse on the first date, because you might just bite yourself in the arse here he he
Cheers

You must be logged in to post a comment.